
[OS] CPU Scheduling
1, 2 장 출제 x (참고자료로 사용) - 여기까지 시험범위
[toc]
Chapter 5: CPU Scheduling
- Basic Concepts
- Scheduling Criteria
- Scheduling Algorithms
- Thread Scheduling
- Multiple-Processor Scheduling
- Real-Time CPU Scheduling
- Operating Systems Examples
- Algorithm Evaluation
Objectives
- To introduce CPU scheduling, which is the basis for multiprogrammed operating systems
- To describe various CPU-scheduling algorithms
- To discuss evaluation criteria for selecting a CPU-scheduling algorithm for a particular system
- To examine the scheduling algorithms of several operating systems
Basic Concepts
- 목적: Maximum CPU utilization obtained with multiprogramming (시험)
- When one process has to wait, OS takes the CPU away from that process and gives the CPU to another process
- The success of CPU scheduling depends on the property
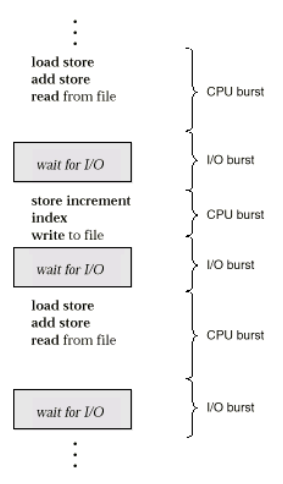
- CPU – I/O Burst Cycle
- Process execution consists of a cycle of CPU execution and I/O wait.
- Process execution begins with CPU burst
- Process execution ends with CPU burst
- CPU burst distribution
- An I/O bound program typically have many very short CPU burst
- A CPU bound program might have a few very long CPU burst
- Distribution can be important in the selection of an appropriate CPU scheduling algorithms
Alternating Sequence of CPU And I/O Bursts
- Maximum CPU utilization obtained with multiprogramming
- CPU–I/O Burst Cycle – Process execution consists of a cycle of CPU execution and I/O wait
- CPU burst followed by I/O burst
- CPU burst distribution is of main concern
Histogram of CPU-burst Times
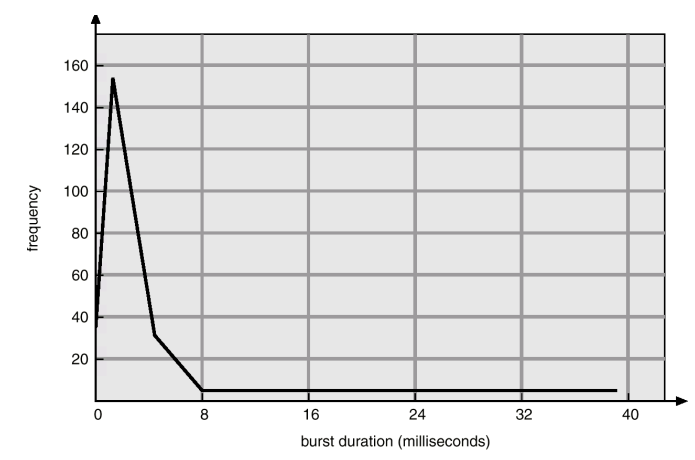
짧은 CPU burst가 많다. -> multi program이 성공할 수 있는 근거
CPU Scheduler(short-term scheduler)(중요)(시험)
- Short-term scheduler selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them.
- Queue may be ordered in various ways
- Ready queue may be implemented as FIFO Q, priority Q, tree, linked list
- The records in the q are generally PCBs of the processes
- CPU scheduling decisions may take place when a process:
- Switches from running to waiting state.
- Switches from running to ready state.
- Switches from waiting to ready. (우선순위가 높은 프로세스의 경우 waiting에서 running으로 갈 여지도 있음)
- Terminates.
- Scheduling under 1 and 4 is nonpreemptive.
- 스스로 끝났거나 waiting으로 갔기 때문에
- Preemptive scheduling is possible under 2 and 3
- 하지만 고려사항이 있음
- Consider access to shared data (data consistency)
- Consider preemption while in kernel mode (kernel data의 protection)
- Consider interrupts occurring during crucial OS activities
- 2번 runnung -> ready : time quantum으로 강제로 CPU를 뺏기 때문
- waiting에서 event가 completion이 되었다면 running을 해야 하는데 ready를 거쳤다가 가게된다.
- 이때, 해당 process가 우선순위가 굉장히 높다면 설령 ready queue에 여러 다른 프로세스가 있어도 곧바로 running으로 갈 수 있는 여지도 있다.
- 즉, 우선순위가 무지하게 높은 프로세스가 waiting이 끝나서 ready로 가는 경우 preemption이 일어난다.
- 하지만 고려사항이 있음
Preemptive vs. Non-preemptive scheduling
- Non-Preemptive scheduling
- Once the CPU has been allocated to a process, the process keeps the CPU until it release the CPU either
- by terminating or
- by switching to the waiting state
- Windows 3.1 Apple Mach OS
- Once the CPU has been allocated to a process, the process keeps the CPU until it release the CPU either
- Preemptive scheduling
- Case of two processes sharing data
- Design of Kernel
- During the process of system call
- UNIX waits either for a system call to complete or for I/O block take place before doing a context switch
- During the process of system call
Dispatcher
- Dispatcher module gives control of the CPU to the process selected by the short-term scheduler; this involves:
- switching context (by OS)
- context가 바뀔 때 해당 process가 block 되면서 남긴 running snapshot 정보를 PCB에 저장해 두었다가 다시 실행 될 때 해당 running snapshot을 복원하여 실행된다.
- switching to user mode
- jumping to the proper location in the user program to restart that program
- switching context (by OS)
- Dispatch latency – time it takes for the dispatcher to stop one process and start another running.
- real-time processing을 할 때, 이를 최소화 시키는 것이 중요함.
Scheduling Criteria(뭐가 더 좋은지를 비교할 수 있는 기준)
- Different algorithms have different properties which may favor 1 class of process over another
- Need criteria to measure performance of various algorithms
- 목적에 따라 다른 기준 적용
- CPU utilization – keep the CPU as busy as possible (시험)
- Percentage of time CPU is busy
- 0~100 % CPU overload(100), too many waiting jobs
- 0: CPU가 사용자 process는 사용하지 않고 오직 OS만
- 100: OS는 실행이 안되고 사용자 process만 계속해서 실행됨.
- 0~100 % CPU overload(100), too many waiting jobs
- Percentage of time CPU is busy
- Throughput – # of processes that complete their execution per time unit
- 단위 시간당 얼마나 많은 process가 실행되었는지
- Size of job affect throughput
- Turnaround time – amount of time to execute a particular process (running + waiting, not ready)(시험)
- N개의 job을 실행하는 데 걸린 총 시간
- process가 실행되고나서 종료될 때까지의 시간
- Total waiting time at all queues & execution time (batch?)
- execution time: running state에서 머문 시간
- total waiting time at all queues: waiting state에서 머문 시간
- Waiting time
- amount of time a process has been waiting in the ready,
- waiting time은 ready에서 머문 시간!!!!!!!!!!!!!
- ready는 실행을 하고 싶은데 못하고 있는 상황이기 때문에
- CPU scheduling alg. Does not affect the amount of time during which a process executes or does I/O
- CPU scheduling 알고리즘이 ready queue에서 대기한 시간에는 영향을 주지만 running 상태나 waiting 상태에서 머문 시간에는 아무런 영향도 주지 않는다.
- It affects only the amount of time that a process spends waiting in the Ready Q
- amount of time a process has been waiting in the ready,
- Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
- 프로세스 요청(실행 요구)된 순간부터 사용자가 응답을 받은 딱 그 순간까지 걸린 시간
Optimization Criteria
- Max CPU utilization
- Max throughput
- Min turnaround time
- Min waiting time
- Min response time
- Fairness
- No particular job should be overly penalized(피해를 받는) through CPU scheduling
- 리눅스의 aging 기법과 같은 애가 이를 해결함.(일정 시간이 지날수록 우선순위가 점점 높아짐)
Scheduling w/o Multiprogramming
- Process A, B : each job requires 4 sec CPU time
- Assuming each exhibit following behavior
- CPU burst 1sec, I/O burst 1 sec -> 완전히 실행되기 위해선 4sec CPU burst, 3 sec I/O burst 필요
- Strategy: 1 job run to completion

- CPU utilization = busy time / total = 8/14 = 57 %
- Throughput = 2 jobs/ 14 secs = 1/7
- Turnaround time
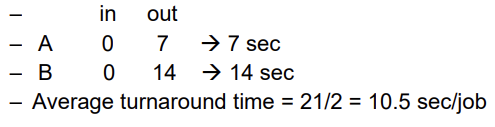
Scheduling with Multiprogramming
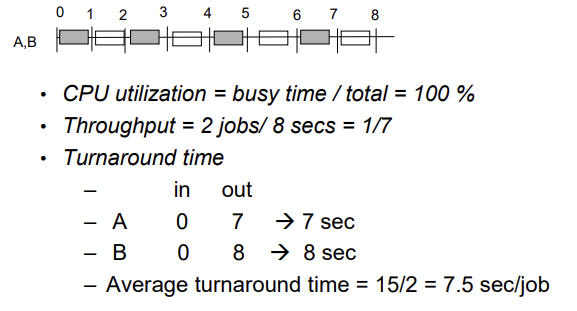
- Throughput = 1/4 (not 1/7, 위 사진에서 오타남)
Scheduling Types
- Non Preemptive (internal stimulus)
- Job allocated CPU and can remain an CPU until
- Completes, I/O request, System call
- Job allocated CPU and can remain an CPU until
- Preemptive (external stimulus)
- A job on CPU can be removed (at any time) and replaced with another user process
First-Come, First-Served(FCFS) Scheduling
- Non-preemptive
- Jobs are given time on CPU in order in which request in (ready queue)
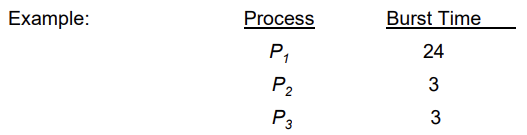
- Suppose that the processes arrive in the order: P1 , P2 , P3 The Gantt Chart for the schedule is:

- Waiting time for P1 = 0; P2 = 24; P3 = 27
- Average waiting time: (0 + 24 + 27)/3 = 17
FCFS Scheduling (Cont.)
Suppose that the processes arrive in the order P2 , P3 , P1 .
- The Gantt chart for the schedule is:

- Waiting time for P1 = 6; P2 = 0; P3 = 3
- Average waiting time: (6 + 0 + 3)/3 = 3
- Much better than previous case.
- Convoy effect - short process behind long process
- short process가 long process 뒤에 서있는 효과
- 쇼핑카트에 물건이 많은 사람이 맨 앞에 서있으면 오래 걸림.
- CPU bound job may benefit
- CPU utilization이 높아지기 때문에
- I/O bound may be penalized
- waiting 시간이 길어지기 때문에
FCFS Scheduling (Cont.)
- Problem
- Wide variance in turnaround time (시험)
- Suceptible(민감) to convoy effect
- Bad for small jobs
- Troublesome for timesharing system
- Advantage
- Easy to implement
- Fast (to pick next job to run)
Shortest-Job-First (SJF) Scheduling
- Associate with each process the length of its next CPU burst.
- Use these lengths to schedule the process with the shortest time.
- Ready list is sorted in increasing order
- Two schemes:
- Non-preemptive
- once CPU given to the process it cannot be preempted until completes its CPU burst.
- Preemptive
- if a new process arrives with CPU burst length less than remaining time of current executing process, preempt(뺏는다.).
- This scheme is known as the Shortest-Remaining-Time-First (SRTF).
- Non-preemptive
- SJF is optimal – gives minimum average waiting time for a given set of processes.
- The difficulty is knowing the length of the next CPU request
- How to know length of the next CPU burst? -> Could ask the user(정확도가 좀 떨어짐)
Example of Non-Preemptive SJF
이해를 위해 실제로 그럴 확률은 적지만 I/O burst가 없는 상황을 예로 보겠다.
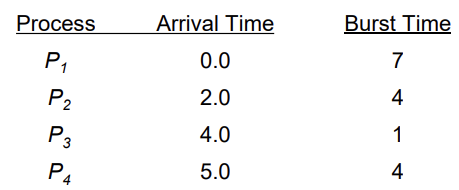
-
SJF (non-preemptive)
-
P2가 먼저 왔더라도 P1이 실행된 이후에 Burst time을 따져봤을 때 P3가 더 짧기 때문에 먼저 실행한다.
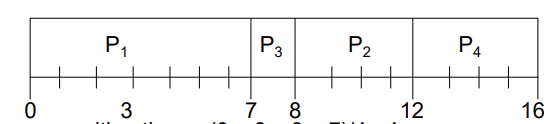
- Average waiting time = (0 + 6 + 3 + 7)/4 = 4
Example of Preempitve SJF
아래 차트 그리는 문제 나올 듯
앞과 같은 예제 - preemptive 버전
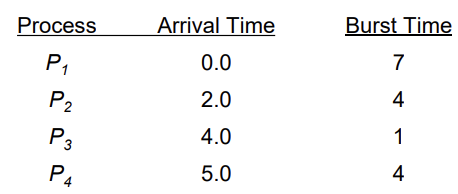
- SJF (preemptive)
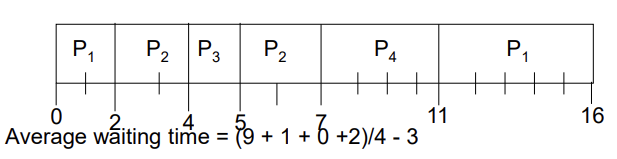
- running 상태에 진입을 했어도 preemption 조건이 만족되면 preempt를 실행한다.
- P1은 0초에 도착하여 P1 밖에 없으므로 실행을 하다가 2초가 되었을 때 P2가 도착하는데 이 때 P1의 남은 Burst Time은 5초이고 P2는 4초이므로 preemption을 진행하여 P2가 CPU를 빼앗아 실행을 진행한다.
- Average waiting time = (9 + 1 + 0 + 2) / 4 = 3
Example of Shortest-remaining-time-first
- Now we add the concepts of varying arrival times and preemption to the analysis
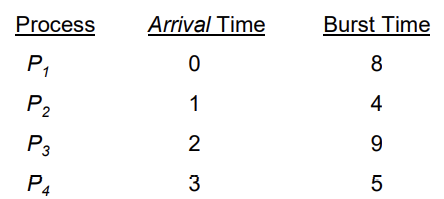
- Preemptive SJF Gantt Chart

- Average waiting time = [(10-1)+(1-1)+(17-2)+5-3)]/4 = 26/4 = 6.5 msec
problem
- Starvation - 프로세스가 끊임없이 필요한 컴퓨터 자원을 가져오지 못하는 상황
- fairness 문제
- The granting of service to particular job is postponed forever
- Infinite wait
- Ex) job A 20
- B 3
- C 3 …
- A가 너무 길어서 다른 프로세스가 올 때마다 다른 프로세스를 실행하느라 A를 계속 실행을 못하게 됨
Determining Length of Next CPU Burst
- Although SJF is optimal, it can not be implemented.
- There is no way to know the length of the next CPU burst
- Can only predict the length.
- The next CPU burst is predicted as an exponential average of the measured lengths of previous CPU burst

- Commonly, α set to ½
Examples of Exponential Averaging
- α =0
- taun+1 = taun
- Recent history does not count.
- Current conditions are assumed to be transient
- α =1
- taun+1 = tn
- 전에 실행되었던 실측치 만으로 tau_n+1 을 결정
- Only the actual last CPU burst counts.
- History is assumed to be old and irrelevant (Fig. 5.3 α =0.5)
- If we expand the formula, we get:
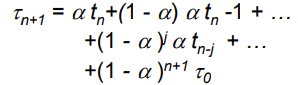
- Since both α and (1 - α) are less than or equal to 1, each successive term has less weight than its predecessor
- 그 전보다 낮은 weight를 가지게 됨
Prediction of the Length of the Next CPU Burst
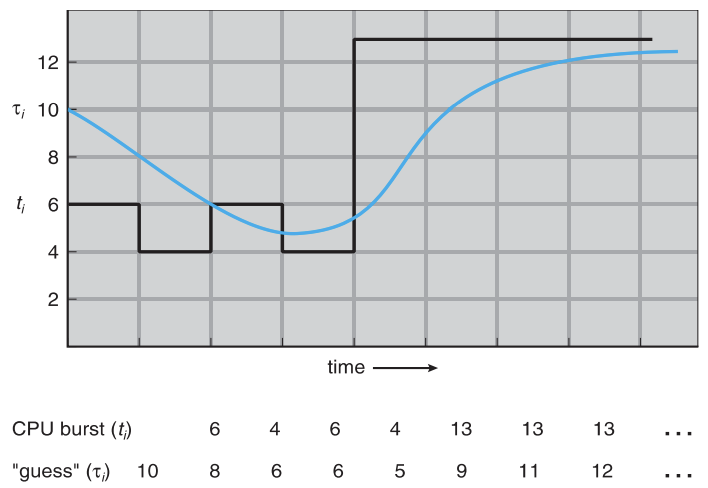
tau가 실측치 t에 거의 근사한 모습이다.
Priority Scheduling
- A priority number (임의로 주어진 integer) is associated with each process
- SJF와는 조금 다름(SJF는 next CPU burst time만으로 결정)
- PS는 각 process에게 주어진 priority number로 결정
- The CPU is allocated to the process with the highest priority (smallest integer = highest priority).
- Preemptive
- Control the length of time a job is on CPU
- 실행 중간에 자기보다 우선순위가 높은 애가 생기면 뺏김.
- Non-preemptive
- Preemptive
- SJF is a priority scheduling where priority is the predicted next CPU burst time.
- Problem define = Starvation –> low priority processes may never execute.
- Solution define = Aging –> as time progresses, increase the priority of the process
- ready queue에 머문 시간이 길어질 수록 priority가 높아짐
Example of Priority Scheduling

- Priority scheduling Gantt Chart
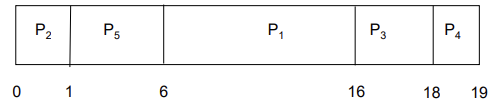
- Average waiting time = 41/5 = 8.2 msec
Round Robin (RR)
- Designed for time sharing systems
- Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue.
- time quantum: running state에서 머무를 수 있는 최대 시간
- If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units.
- fairness 보장하는 방식!!!
- Performance of RR depends heavily on the size of Time Quantum
- q large => FIFO
- Good for CPU bound, bad for interactive job
- Less context switch
- q small =>
- Processor sharing
- Appears(착각) to user as though each of n processes has its own processor running at 1/n the speed of real processor
- q must be large with respect to context switch, otherwise overhead is too high.
- context switching을 너무 자주 하면서 생기는 overhead
- Processor sharing
- q large => FIFO
Example: RR with Time Quantum = 20

- The Gantt chart is:
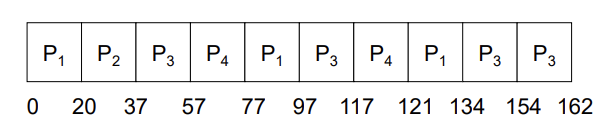
- P2는 burst time이 17이라 20이라는 time quantum을 다 사용하지 않고 마무리됨
- Typically, higher average turnaround than SJF, but better response.
- q should be large compared to context switch time
- q usually 10ms to 100ms, context switch < 10 usec
How a Smaller Time Quantum Increases Context Switches
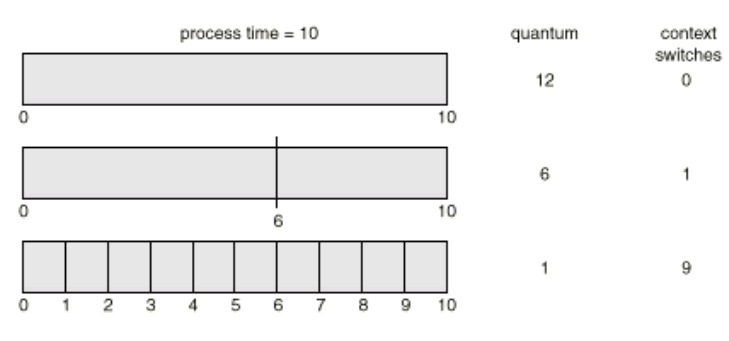
high time quantum makes overhead
Turnaround Time Varies With The Time Quantum
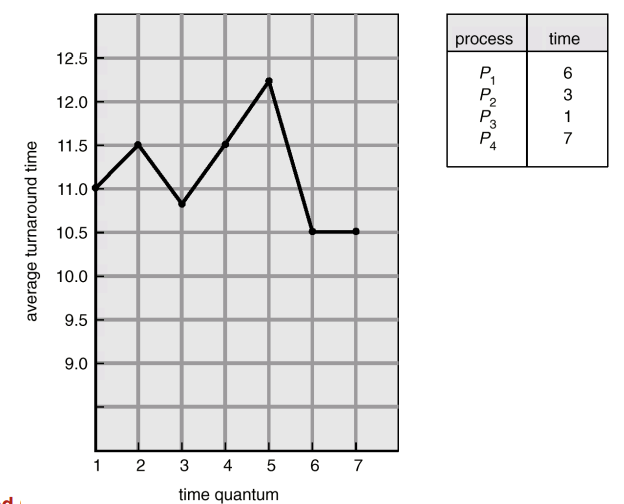
올바른 time quantum 값을 정하기 어려움(비례하거나 반비례하지 않음)
Mulitilevel Queue Scheduling
- Ready queue is partitioned into separate queues: foreground (interactive) background (batch)
- Process permanently in a given queue
- Each queue has its own scheduling algorithm,
- foreground – RR (Round Robin)
- background – FCFS (First come First served)
- Scheduling must be done between the queues.
- Fixed priority preemptive scheduling;
- i.e., serve all from foreground then from background. (foreground에 하나라도 있으면 그거먼저(preemption) scheduling)
- Possibility of starvation.
- Time slice – each queue gets a certain amount of CPU time which it can schedule amongst its processes; i.e., 80% to foreground in RR, 20% to background in FCFS
- starvation reduces
- Fixed priority preemptive scheduling;
Multilevel Queue Scheduling
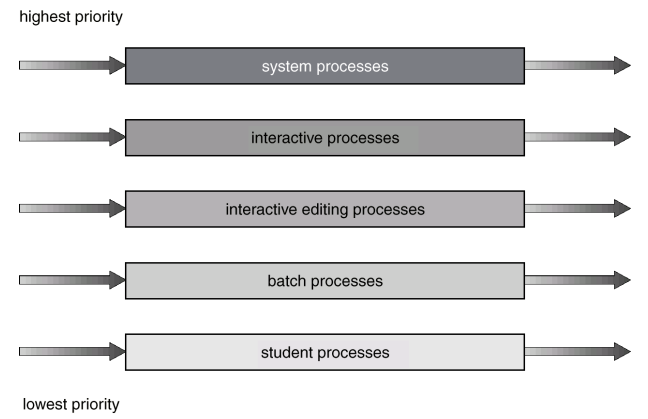
Multilevel Feedback Queue Scheduling
feedback을 허용하는 방식
- In a Multi-level queue scheduling, processes are permanently assigned to a queue on entry to the system (queue 간의 이동을 금지)
- Processes do not move between queues
- A process can move between the various queues;
- If a process uses too much CPU time, it will be moved to a lower priority queue
- A process that waits too long in a lower priority queue may be moved to a higher priority queue
- aging can be implemented this way. (prevents starvation)
- Multilevel-feedback-queue scheduler defined by the following parameters:
- number of queues
- scheduling algorithms for each queue
- method used to determine when to upgrade a process
- method used to determine when to demote a process
- method used to determine which queue a process will enter when that process needs service
- I/O bound or interactive processes to the higher priority q
Multilevel Feedback Queues
interactive 성격을 띠는 process는 CPU burst time이 짧기 때문에 quantum 값을 작게 준다.
- 아래로 갈 수록 우선순위가 낮은 큐
우선순위가 낮아질 수록 quantum 값을 크게 줌.
FCFS는 time quantum이 존재하지 않는다.
- 사용할 수 있다면 CPU time을 만들어 바로 사용할 수 있는 방식이기 때문에
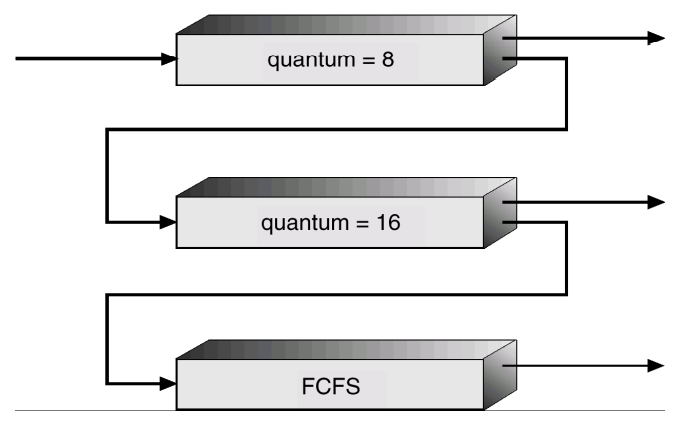
Example of Multilevel Feedback Queue
- Three queues:
- Q0 – RR, time quantum 8 milliseconds
- Q1 – RR, time quantum 16 milliseconds
- Q2 – FCFS
- Scheduling
- A new job enters queue Q0 which is served FCFS.
- When it gains CPU, job receives 8 milliseconds.
- If it does not finish in 8 milliseconds, job is moved to queue Q1 .
- At Q1 job is again served FCFS and receives 16 additional milliseconds.
- If it still does not complete, it is preempted and moved to queue Q2
- A new job enters queue Q0 which is served FCFS.
- 우선순위가 높은 곳에서도 안 끝나면 넌 낮은데로 가버렷! 그래도 안 끝나면 넌 FCFS로 가버렷!(무조건 끝나게)
Review: Scheduler Activations
- Communication between kernel and thread library
- Both M:M and Two-level models require communication to maintain the appropriate number of kernel threads allocated to the application
- This communication allows an application to maintain the correct number kernel threads for performance
- Typically use an intermediate data structure between user and kernel threads - lightweight process (LWP) : 자료구조의 일종(유저스레드와 커널스레드에 mapping 정보를 담는)
- 한 애플리케이션에서 사용될 커널 스레드의 갯수를 타협하는 애
- Appears to be a virtual processor on which process can schedule user thread to run
- Each LWP attached to kernel thread
- OS schedules kernel threads to run on a physical processor
- If a kernel thread blocks, LWP blocks, and user-level thread attached to LWP also blocks
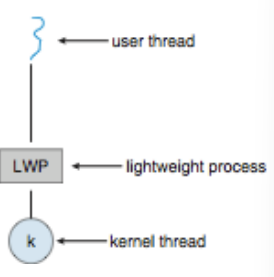
- OS의 CPU scheduler가 하는 결정: 여러 개 커널 thread 중에서 어떤 커널 thread가 먼저 실행 될지
- CPU에 의해서 실행되기 때문에 kernel thread라고 불리는 것.
- user level(thread library)하는 결정: 어떤 user thread가 LWP에 할당될 것인가
Review: Scheduler Activations
How many LWPs(i.e., kernel thread) to create? (for user thread)
- CPU-bound application running on a processor:
- only one thread can run at a time, so one LWP is sufficient
- Other type of application may require multiple LWPs (concurrent threads)
- An LWP is required for each concurrent blocking system call
- Scheduler activations
- a communication mechanism from the kernel to the thread library
- Kernel provides an application with a set of LWPs
- Kernel must inform an application about certain events (upcall)
- Ex: notify which application thread is about to block -> 그럼 다른 유저스레드 할당할 수 있겠네??
- Upcalls are handled by the thread library with an upcall handler, which must run on a LWP – Kernel allocates a new LWP to the application,
- available kernel thread의 갯수를 조정해주는 -> upcall
- upcall handler 실행, blocking thread의 state save
- blocking thread를 실행하던 기존 LWP는 반납
- upcall handler는 이 LWP에 다른 thread를 scheduling 함.
- Blocking 해제시, event upcall 처리용 LWP, block되었던 thread 실행용 LWP 할당
Thread Scheduling: Contention scope
- When threads supported by OS, threads (not processes) are scheduled,
- user-level과 kernel-level threads의 차이는 scheduling 되는 방법에 있음
- User-level threads are managed by thread library, kernel is unaware of them
- To run on CPU, user-level threads should be mapped to kernel-level threads
- Typically use an intermediate data structure between user and kernel threads called lightweight process (LWP)
- Appears to be a virtual processor on which process can schedule user thread to run
- Thread library schedules user-level threads to run on available LWP
- CPU에 의해 실행되는 것을 의미하는 것이 아님.
- Each LWP attached to kernel thread
- How many LWPs to create? - managed by thread library
- Known as process-contention scope (PCS) since scheduling competition is within the process (시험)
- 어플리케이션 내에서
- PCS is done via priority set by programmer
- Both M:M and Two-level models require communication to maintain the appropriate number of kernel threads allocated to the application
Contention scope(시험)
- Kernel thread are scheduled onto available CPU is system-contention scope (SCS) – competition among all threads in system
- System using O:O(one-to-one) model (window, Linux) schedules threads using only SCS
- 선발할 이유가 없음, 어차피 OS는 소속을 보지 않기 때문에
Pthread Scheduling
- We studied POSIX Pthread programming in previous chapter
- pthread_create( )
- API allows specifying either PCS or SCS during thread creation
- PTHREAD_SCOPE_PROCESS schedules threads using PCS scheduling
- PTHREAD_SCOPE_SYSTEM schedules threads using SCS scheduling
- Can be limited by OS – Linux and Mac OS X only allow PTHREAD_SCOPE_SYSTEM
Pthread Scheduling API(시험)
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* first inquire on the current scope */
if (pthread_attr_getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM");
else
fprintf(stderr, "Illegal scope value.\n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread_exit(0);
}
Multiple-Processor Scheduling
- CPU scheduling more complex when multiple CPUs are available.
- Multiprocessor system
- Systems that provide multiple processors, each one contains single-core CPU
- Currently, applies to
- Multi-core CPU
- Multi-threaded cores
- NUMA(non uniform memory access) systems
- CPU마다 자기만 access하는 memory가 있다. (그래서 memory마다 접근하는 시간이 다 다르다.)
- Heterogeneous multiprocessing (하는 일 특화)
- Homogeneous processors within a multiprocessor.
- Any available processor can be used to run any process in the queue
- Heterogeneous processors
- Only programs compiled for a given processor’s instruction set could be run on that processor
- Allows several processes to run in parallel by providing multiple physical processors
Approaches to Multiple-Processor Scheduling
- Asymmetric multiprocessing
- only one processor handles scheduling decision, I/O processing and system activities such as accessing the system data structures
- cpu 중에 대장인 master cpu가 있다.
- 한 cpu가 스케쥴링, I/O 프로세싱을 지시하고 나머지 cpu는 시키는 일을 받아서 한다.
- The other processors only execute use code
- alleviating the need for data sharing. (메모리 쉐어링을 할 필요가 없음.)
- Much simpler than symmetric multiprocessing
- only one processor handles scheduling decision, I/O processing and system activities such as accessing the system data structures
- Symmetric multiprocessing (SMP) - each processor is self-scheduling,
- 모두 동등한 cpu이다. 스케쥴링도 cpu 별로 각자 알아서 한다
- all processes in common ready queue (has race condition problem),
- or each has its own private queue of ready processes
- Currently, most common
- Load sharing
- Common ready queue, and are scheduled onto any available processor
Multiple-Processor Scheduling - Load Balancing
- If SMP, need to keep all CPUs loaded for efficiency
- Load balancing attempts to keep workload evenly distributed
- Push migration – periodic task checks load on each processor, and if found pushes task from overloaded CPU to other CPUs
- 실행 상태(live)에서 이주 시킨다.
- Pull migration – idle(한가한) processors pulls waiting task from busy processor
Processor affinity(친화적인)
-
CPU 별로 특성이 있는 경우
- 실행중인 프로세서에서 계속 실행시키면
- Cache memory 잔상을 이용하여 fast successive memory access 효과 기대
- common ready queue
- private ready queue : 보다 나은 processor affinity 효과
- process has affinity for processor on which it is currently running
- soft affinity : process affinity를 반드시 보장해야 하는 것은 아닌
- 되도록이면 이렇게 하자
- hard affinity : 반드시 보장해야 하는
- 무조건 이렇게 해야 해
- Variations including processor sets
- soft affinity : process affinity를 반드시 보장해야 하는 것은 아닌
- 프로세스가 돌다가 waiting 상태가 되었을 때 다시 돌아오려고 할 때 돌던 곳으로 돌아와서 실행하는 것이 좋은가 아니면 load balance를 고려했을 때 해당 프로세스가 실행될 지점의 load가 큰 경우 어떻게 해야 하는가?
NUMA and CPU Scheduling
Memory architecture도 processor affinity에 영향을 줌
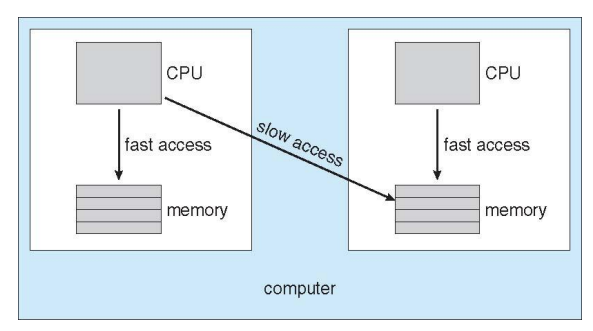
Note that memory-placement algorithms can also consider affinity
Multicore Processors
- Recent trend to place multiple processor cores on same physical chip
- Each core appears to OS to be a separate logical CPU
- Faster and consumes less power
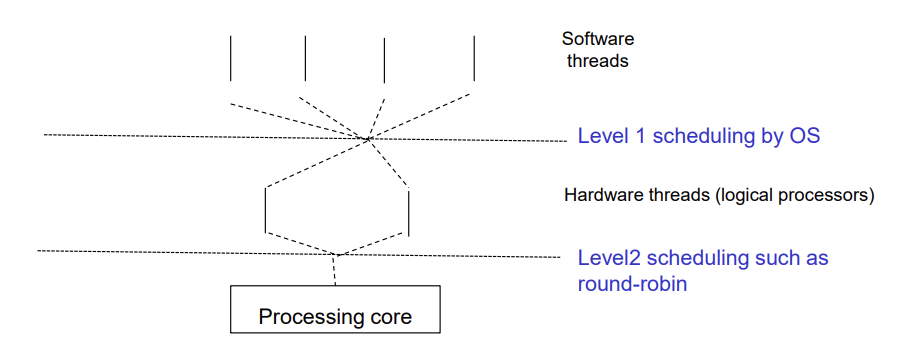
Multicore Processors
- Memory stall
- 메모리 access 와 CPU 성능 차이 때문에 CPU가 놀고 있는 것
- Resulted from speed gap between CPU and memory, cache miss
- Multiple threads per core also growing
- Takes advantage of memory stall to make progress on another thread while memory retrieve happens
- Multithreaded processing core in which several hardware threads are assigned to each core (chip multi-threading or hyper-threading)
- If one hardware thread stalls while waiting for memory, the core can switch to another thread
- Oracle Sparc M7 processor 8 threads per core, 8 cores per processor, thus providing OS with 64 logical CPUs
atomic operation: instruction cycle을 중지시킬 interrupt는 존재하지 않음.
Multithreaded Multicore System
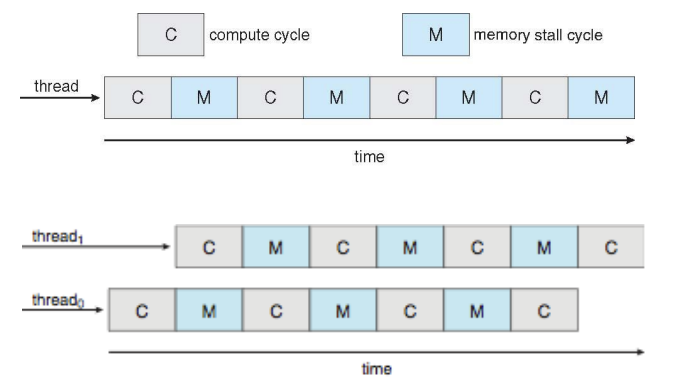
hyper thread: memory stall 시간 안에 여러 개의 thread를 concurrent하게 실행 함.
Heterogeneous multiprocessing
- Homogeneous multiprocessing
- All processors are identical in terms of capabilities, allowing any thread can run any processing core
- Memory access time can be vary according to load balancing, processor affinity policy,
- Mobile systems include multi-core architecture that run the same instruction set
- But each core may be different in terms of clock speed, power consumption management
- For ARM processors, Higher performance big core consumes more energy
- Little core consumes less energy
- CPU scheduler assign tasks considering the characteristics of task
Real-Time systems
-
일 처리가 의미있는 시간 안에 완료되는 System
- Hard real-time systems - required to complete a critical task within a guaranteed amount of time.
- Resource reservation
- Scheduler should know exactly how long each os function takes to perform and be guaranteed to take a maximum amount of time
- Such a guarantee is impossible in a general purpose system
- 프로세스가 탑재되기 전에 실행 시간이 미리 정해져 있음
- Soft real-time systems – requires that critical processes receive priority over less fortunate ones.
- 전화가 연결될 때 ring-back tone과 같은(특정 시간 안에 끝나는 것이 보장되지 않음)
- ring-back tone이 routing이 빠르게 되면 금방 들리겠지만 routing이 느리게 되면 몇십초 있다가 들릴 수 있다.
- Priority scheduling w/O aging
- Starvation possible
- Dispatch latency must be small
- The smaller the dispatch latency, the faster a real-time process can start execution once it is runnable
- Many os waits for either a system call to complete or for an I/O block to take place before doing a context switch
- Dispatch latency can be long
- 전화가 연결될 때 ring-back tone과 같은(특정 시간 안에 끝나는 것이 보장되지 않음)
Real-Time Scheduling
- In general, real-time operating systems must provide:
- Preemptive, priority-based scheduling
- Preemptive kernels
- Latency must be minimized
kernel code를 실행 중에 우선순위가 높은 프로세스가 들어오면 preemption
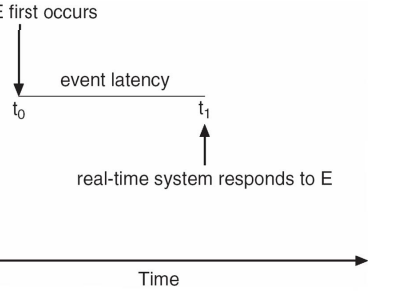
Event Latency
- Event latency is the amount of time from when an event occurs to when it is serviced.
- Software event – timer expiration
- Hardware event
- Different latency requirements for the events
- It should be minimize event latency
Real-Time CPU Schduling
- Soft real-time systems - no guarantee as to when critical realtime process will be scheduled
- Hard real-time systems - task must be serviced by its deadline
- Two types of latencies affect performance
- Interrupt latency – time from arrival of interrupt at CPU to start of routine that services interrupt
- interrupt가 발생하고 (CPU가 인지하고) ISR(Interrupt Service Routine)이 실행되는 시간까지의 간격
- Dispatch latency – time for schedule to take current process off CPU and switch to another
- 현재 돌고있는 프로세스를 끌어내리고 새로 run 할 프로세스로 바꾸는 시간
- Interrupt latency – time from arrival of interrupt at CPU to start of routine that services interrupt
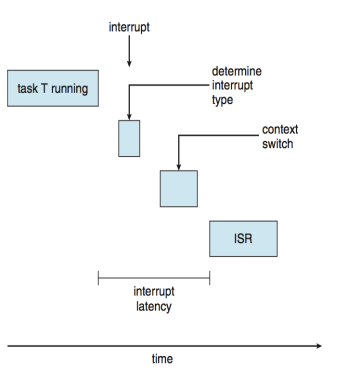
-
In Linux ISR이 두 개로 나눠짐, Top half, Bottom half
- interrupt를 CPU가 감지하기 까지 걸린 시간(delay)
- interrupt 우선순위가 낮을 수록 이 delay가 커진다.
- context switch: 프로세스의 잔상을 저장
- 우선순위가 높은 놈이 있으면 interrupt를 처리하고 다시 되돌아 온다는 보장이 없는데 그러면 되돌아오지 않기 때문에 context switching이 필요하다.
- interrupt latency: 이벤트가 발생한 시점부터 ISR이 딱 실행될 때까지의 시간
Interrupt latency
- Kernel Data structure가 수정되는 동안 Interrupt disable 된 시간 최소화
Dispatch latency(시험)
- Amount of time required for dispatcher to stop one process and start another.
- To keep dispatch latency low, we need to allow
- Conflict phase of dispatch latency (수 msecs): (시험)
- Preemption of any process running in the kernel
- Release by low-priority processes resources needed by a high-priority
- 우선순위가 낮은 프로세스가 자원을 갖고 있는 경우 priority inversion
- prioity inversion: 순식간에 우선순위를 확 올려줘서 빨리 끝내게 하는
- ex) system call을 실행 중에 우선순위가 높은 놈이 큐에 들어오면 preemption이 진행되어야 하는데 안전하게 system call이 끝난 뒤에 하자니 real-time system이 보장되지 않기 때문에 이를 kernel에서 뺏어야 하는데 우선 순위가 높은 놈이 지금 쓰고 있던 놈의 자원을 필요로 할 수 있기 때문에 이를 priority inversion을 사용해서 너 높은 우선순위 줄테니까 빨리 끝내!!! 하고 끝나면 다시 원래의 값으로 돌린다.
- Conflict phase of dispatch latency (수 msecs): (시험)
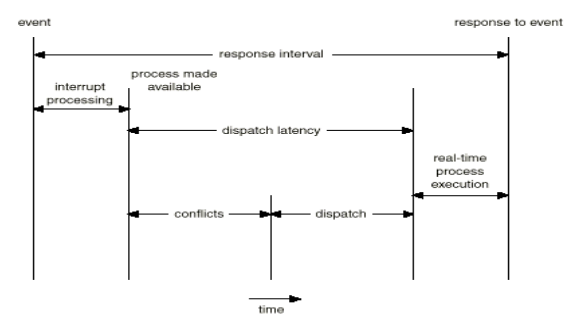
- interrupt processing: interrupt latency + ISR time
- dispatch latency
Dispatch latency
- Insert preemption points in long duration system calls, which check to see whether a high priority process needs to be run
- Context switch can be taken place only at preemption points
- Preemption points can be placed at only safe locations in kernel
- Kernel data structures are not being modified
- Only a few preemption points possible
- Make the entire kernel pre-emptible
- All kernel DS must be protected through the use of synchronization mechanism
- Priority inversion
- Higher priority process needs to read or modify kernel data that are currently being accessed by lower priority process
- Higher priority process would be waiting for a lower priority one to finish
- Can be solved by priority inheritance protocol, in which all low priority processes inherit the high priority until they are done with the resource in question
- When they are finished, their priority reverts to its original value
Priority-based Scheduling
- For real-time scheduling, scheduler must support preemptive, priority-based scheduling
- But only guarantees soft real-time
- For hard real-time must also provide ability to meet deadlines
- deadline이 중요!
- Admission control
- Processes have new characteristics: periodic ones require CPU at constant intervals
- Has processing time t, deadline d, period p
- 0 ≤ t ≤ d ≤ p
- Rate of periodic task is 1/p
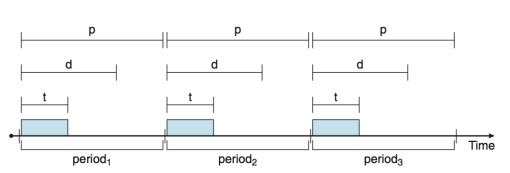
- p: event 처리 시간
- d: deadline
- d < p 이면 real time 프로세싱이라고 할 수 없음
- 데드라인이 지나서 처리하는 것은 real time 의 의미를 살리지 못한 것
- d > p 이면 처리 못한 애가 있는데 다음 거를 처리하게 되는 경우 발생
Rate Monotonic Scheduling (1)(시험)
rate monotonic: 주기의 역순으로 우선순위를 설정
즉, 빈도(frequency)가 높은 애가 높은 우선순위를 갖는다.
- Schedules periodic tasks using a static priority with preemption
- A priority is assigned based on the inverse of its period -> 1/p
- Shorter periods = higher priority;
- Longer periods = lower priority
- Period: P1 = 50, p2 = 100
- Processing time: t1 = 20, t2 = 35
- CPU utilization = ti/pi , p1 -> 20/50 = 0.4, p2 -> 35/100 = 0.35
- 실제 처리에 필요한 시간의 비율
- Total CPU utilization = 0.75 -> both meet their deadlines
- 둘 다 deadline 안에 처리가 가능하다.
Rate Monotonic Scheduling (2)
만약 우선순위가 p이면 (not 1/p)
deadline이 주기랑 같다고 가정
-
If p2 is assigned higher priority than p1 -> p1 will miss its deadline
-
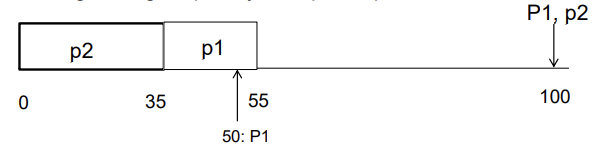
-
p2는 deadline안에 처리가 됨.
-
-
P1 is assigned a higher priority than P2 . (rate monotonic) -> both can meet deadlines
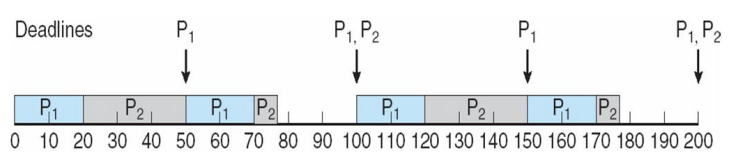
- p2가 30초 동안 실행되다가 P1 주기에 도달하여 이제 누가 우선순위가 높은지 따져봐야 되는데 P1의 deadline이 더 짧기 때문에 P2를 preemption하게 된다.
- P1=50, P2=100
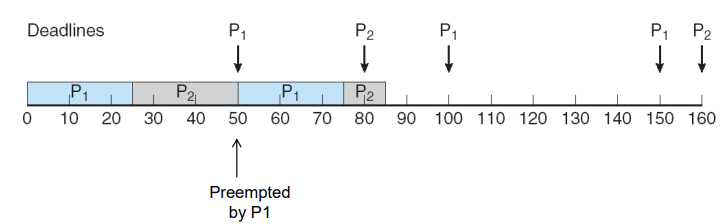
Missed Deadlines with Rate Monotonic Scheduling (3)
rate monotonic scheduling은 완벽한 하드 리얼타임 시스템이 될 수 없음.
- Optimal in which static priority is used
- Period: P1 = 50, p2 = 80 -> p1 will be assigned higher priority
- Processing time: t1 = 25, t2 = 35
- Total CPU utilization = (25/50) + (35/80) = 0.94 -> p2 can not meet deadline
- 6%가 남아있기 때문에 가능할 것처럼 보이지만 진행 과정을 보면 P2가 끝나지 못했는데 P2 주기가 다가온 것을 볼 수 있다.
Earliest Deadline First Scheduling (EDF)(시험)
- 지금시점으로부터 deadline이 제일 임박한 애를 먼저 스케쥴링
- 주기가 짧은 놈이 preemption 되는 것이 아니라, 데드라인이 가장 작은 놈에게 preemption을 줌
-
하드 리얼타임 시스템이 가능함!
- Dynamic Priorities are assigned according to deadlines:
- Rate Monotonic과 다르게 우선순위가 계속해서 바뀐다.
- rate monotonic은 한 번 결정되면 바뀌지 않음(주기가 바뀌는 것이 아니기 때문에)
- the earlier the deadline, the higher the priority;
- 지금 시점에서!!!!!!!!
- the later the deadline, the lower the priority
- Rate Monotonic과 다르게 우선순위가 계속해서 바뀐다.
- Priorities are adjusted to reflect the deadline of newly runnable process
- Period: P1 = 50, p2 = 80 -> p1 will be assigned higher priority
- Processing time: t1 = 25, t2 = 35
- Rate3 – can not meet, EDF – can meet
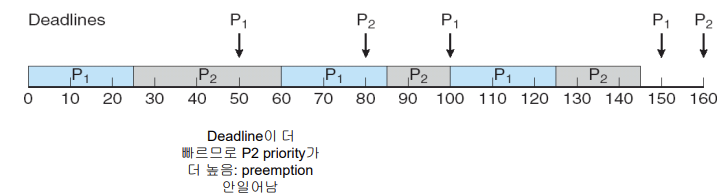
- 0초에 P1, P2가 동시에 시작
- P1이 처음에 우선순위가 높기 때문에 먼저 실행
- 25초동안 P1 실행
- P2처리하다가 P1 주기에서 이제 누가 우선순위가 높은지 판정하게 되는데 P1은 이미 끝났기 때문에 deadline이 100이고 P2는 아직 실행 중이기 때문에 deadline이 80이므로 P2가 더 높은 우선순위를 차지하게 되어 preemption이 일어나지 않고 계속 실행된다.
- 그러다가 P2 주기에서
- P2 deadline: 160
- P1 deadline: 100
- 이므로 P1이 우선순위라 그대로 실행을 진행하고
- 다시 P1 주기에서는
- P2 deadline: 160
- P1 deadline: 150
- 이므로 P1이 우선순위가 더 높기 때문에 현재 실행중이던 P2 process를 preemption 하여 P1 process를 실행한 것이다.
rate monotonic 보다 real time process를 훨씬 더 보장!!!!
Proportional Share Scheduling
- T shares are allocated among all processes in the system
- 전체 CPU time의 비율
- An application receives N shares where N < T
- This ensures each application will receive N / T of the total processor time
- Must work with admission control policy to guarantee that an application receives its allocated shares of time
- 일정 시간의 비율을 할당 받는 것이 보장되지 않으면 거부하는 policy
POSIX Real-Time Scheduling
- The POSIX.1b standard
- API provides functions for managing real-time threads
- Defines two scheduling classes for real-time threads:
- SCHED_FIFO - threads are scheduled using a FCFS strategy with a FIFO queue. There is no time-slicing for threads of equal priority
- SCHED_RR - similar to SCHED_FIFO except time-slicing occurs for threads of equal priority
- SCHED_OTHER – system specific
- Defines two functions for getting and setting scheduling policy:

POSIC Real-Time Scheduling API
#include <pthread.h>
#include <stdio.h>
#define NUM THREADS 5
int main(int argc, char *argv[])
{
int i, policy;
pthread t tid[NUM THREADS];
pthread attr t attr;
/* get the default attributes */
pthread attr init(&attr);
/* get the current scheduling policy */
if (pthread attr getschedpolicy(&attr, &policy) != 0)
fprintf(stderr, "Unable to get policy.\n");
else {
if (policy == SCHED OTHER) printf("SCHED OTHER\n");
else if (policy == SCHED RR) printf("SCHED RR\n");
else if (policy == SCHED FIFO) printf("SCHED FIFO\n");
/* set the scheduling policy - FIFO, RR, or OTHER */
if (pthread attr setschedpolicy(&attr, SCHED FIFO) != 0)
fprintf(stderr, "Unable to set policy.\n");
/* create the threads */
for (i = 0; i < NUM THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM THREADS; i++)
pthread join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread exit(0);
}
이 아래의 OS example은 시험에 안나옴 (그 다음은 나옴)
real time processing까지 시험범위
Operating System Examples
- Linux scheduling
- Solaris scheduling
- Windows XP scheduling
Solaris
- Priority-based scheduling
- Six classes available
- Time sharing (default)
- Interactive
- Real time
- System
- Fair Share
- Fixed priority
- Given thread can be in one class at a time
- Each class has its own scheduling algorithm
- Time sharing is multi-level feedback queue
- Loadable table configurable by sysadmin
Solaris Dispatch Table
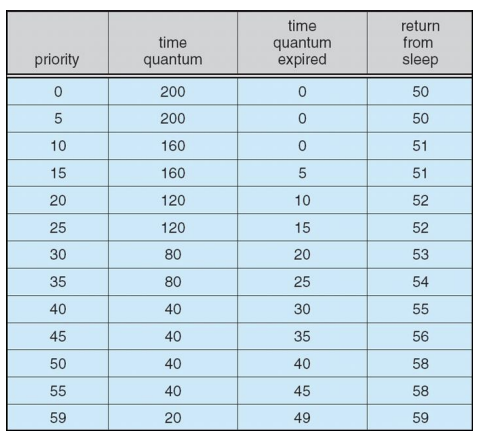
Solaris Scheduling
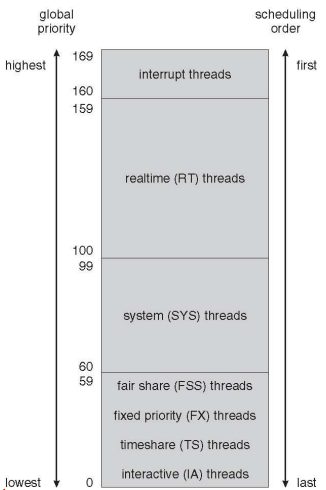
Solaris Scheduling (Cont.)
- Scheduler converts class-specific priorities into a per-thread global priority
- Thread with highest priority runs next
- Runs until (1) blocks, (2) uses time slice, (3) preempted by higherpriority thread
- Multiple threads at same priority selected via RR
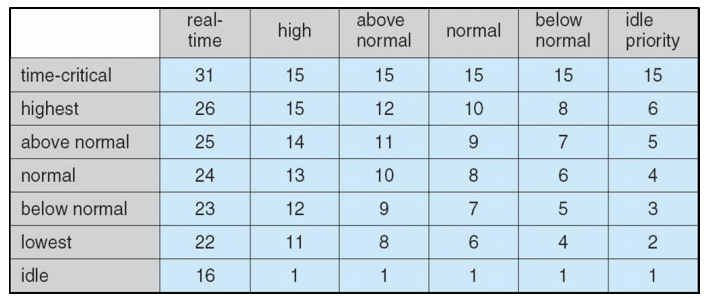
Windows Scheduling
- Windows uses priority-based preemptive scheduling
- Highest-priority thread runs next
- Dispatcher is scheduler
- Thread runs until (1) blocks, (2) uses time slice, (3) preempted by higher-priority thread
- Real-time threads can preempt non-real-time
- 32-level priority scheme
- Variable class is 1-15, real-time class is 16-31
- Priority 0 is memory-management thread
- Queue for each priority
- If no run-able thread, runs idle thread
Windows Priority Classes
- Win32 API identifies several priority classes to which a process can belong
- REALTIME_PRIORITY_CLASS, HIGH_PRIORITY_CLASS, ABOVE_NORMAL_PRIORITY_CLASS,NORMAL_PRIORITY_CLASS, BELOW_NORMAL_PRIORITY_CLASS, IDLE_PRIORITY_CLASS
- All are variable except REALTIME
- A thread within a given priority class has a relative priority
- TIME_CRITICAL, HIGHEST, ABOVE_NORMAL, NORMAL, BELOW_NORMAL, LOWEST, IDLE
- Priority class and relative priority combine to give numeric priority
- Base priority is NORMAL within the class
- If quantum expires, priority lowered, but never below base
Windows Priority Classes (Cont.)
- If wait occurs, priority boosted depending on what was waited for
- Foreground window given 3x priority boost
- Windows 7 added user-mode scheduling (UMS)
- Applications create and manage threads independent of kernel
- For large number of threads, much more efficient
- UMS schedulers come from programming language libraries like C++ Concurrent Runtime (ConcRT) framework
Windows XP Priorities
Linux Scheduling Through Version 2.5
- Prior to kernel version 2.5, ran variation of standard UNIX scheduling algorithm
- Did not support SMP system
- Runnable task의 개수가 증가하면 성능 저하
- Version 2.5 moved to constant order O(1) scheduling time
- SMP system 지원,
- Processor affinity. Load balancing 지원
- runnable task 개수에 상관없이 constant scheduling
- Worked well, but poor response times for interactive processes
- SMP system 지원,
Linux Scheduling in Version 2.6.23 +
-
O(1) provides excellent performance for SMP, but poor response time for interactive tasks - Completely Fair Scheduler (CFS)
-
Scheduling is based on Scheduling classes
-
Each class is assigned a specific priority
-
2 scheduling classes included, others can be added
-
Different scheduling algorithms can be used for different scheduling classes
-
Default - CFS
-
real-time
-
-
Scheduler picks highest priority task in highest scheduling class
-
-
Priority에 따라 고정 길이의 time quantum을 제공하던 방식 개선
- Rather than quantum based on fixed time allotments, CFS assigns a proportion of CPU time to each task
- This proportion is calculated based on nice value from -20 to +19
- CFS does not use discrete values of time slices and instead identifies target latency
- interval of time during which task should run at least once
- Proportions of CPU time are allocated from the value of targeted latency
- Target latency can increase if number of active tasks increases
- CFS scheduler does not directly assign priorities
- CFS records how long each task has run by maintaining per task virtual run time in variable vruntime
- Vruntime is associated with decay factor based on priority of task
- lower priority is higher decay rate
- high priority is lower decay rate
- Normal default priority (nice value 0) yields
- virtual run time = actual run time
- Low priority : virtual run time > actual run time
- High priority : virtual run time < actual run time
- Vruntime is associated with decay factor based on priority of task
- To decide next task to run, scheduler picks task with lowest virtual run time
- Assume that two tasks have the same nice values, one task is I/O bound, the other is CPU bound
- The value of vruntime will eventually be lower for I/O bound task than for CPU bound task
- Higher priority will be given for I/O bound task
- if CPU bound task is executing when I/O bound task becomes eligible to run
- Preemption by I/O bound task: Preemptive, priority based
Linux Scheduling (Cont.)
- Real-time scheduling according to POSIX.1b
- Real-time tasks have static priorities (0 ~ 99)
- Any task scheduled using SCHED_FIFO or SCHED_RR real-time policy runs at higher priority than normal non-real-time tasks
- All other normal tasks dynamic based on nice value plus or minus 5
- Nice value of -20 maps to global priority 100
- Nice value of +19 maps to priority 139
- Map into global priority with numerically lower values indicating higher priority
- Interactivity of task determines plus or minus
- More interactive -> more minus
- Priority recalculated when task expired
- This exchanging arrays implements adjusted priorities

Priorities and Time-slice length
CPU를 얼마나 사용했냐에 따라서 등급을 조정
- Two priority ranges: time-sharing and real-time
- real-time은 우선순위가 동적으로 조정되지 않음
- Real-time range from 0 to 99 and nice value from 100 to 140
- Higher priority gets larger q
- 우선순위가 높을 수록 time quantum을 높게 줌.
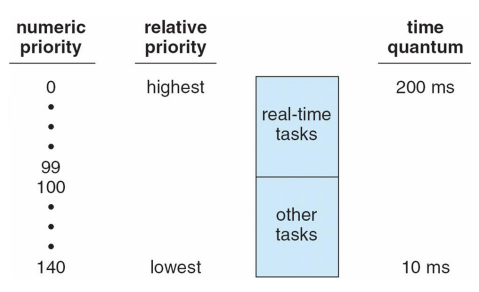
- real-time이 100개, other task(normal task)가 40개
- real-time은 철저한 우선순위 기반
- normal task는 계속해서 우선순위가 바뀜
- 주어진 time quantum을 다 쓰는 경우에 우선 순위가 내려감
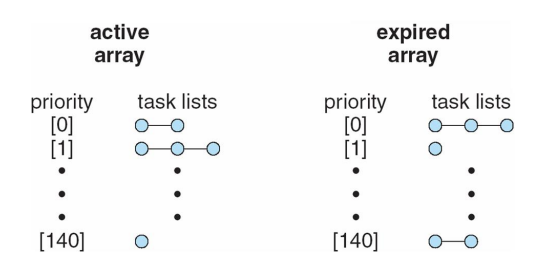
List of Tasks Indexed According to Priorities
- Task runnable as long as time left in time slice (active)
- 다 실행되지 못하고 preemption 된 경우는 active queue에 머물러 있고
- If no time left (expired), not runnable until all other tasks use their slices
- time slice가 남아있는 경우 expired queue로 넘어간다.
- All runnable tasks tracked in per-CPU runqueue data structure
- Two priority arrays (active, expired)
- Tasks indexed by priority
- When no more active, arrays are exchanged
- active queue에 있는 것들이 전부 expired로 넘어가면 그때 두 queue(active, expired)는 바뀌게 된다.
CFS Performance
Algorithm Evaluation
- How to select CPU-scheduling algorithm for an OS?
- Determine criteria, then evaluate algorithms
- Deterministic modeling
- Type of analytic evaluation
- Takes a particular predetermined workload and defines the performance of each algorithm for that workload
- Simple but only answer to specific cases
- Consider 5 processes arriving at time 0

Deterministic Evaluation
- For each algorithm, calculate minimum average waiting time
- Simple and fast, but requires exact numbers for input, applies only to those inputs
- FCS is 28ms
- Non-preemptive SFJ is 13ms:
- RR is 23ms:
- FCS is 28ms



Queueing Models
- Generally no static set of processes to use for deterministic modeling
- Compute criterion using two distributions
- Describes the arrival of processes, and CPU and I/O bursts probabilistically
- Distribution of CPU and I/O bursts
- Arrival-time distribution - Distribution of times when processes arrive in the system
- Commonly exponential, and described by mean
- Computes average throughput, utilization, waiting time, etc
- Computer system described as network of servers,
- each server has queue of waiting processes
- CPU with ready queue, I/O with device queue
- Knowing arrival rates and service rates
- Computes utilization, average queue length, average wait time, etc
- each server has queue of waiting processes
Little’s Formula
-
n = average queue length
-
W = average waiting time in queue
-
λ = average arrival rate into queue
-
Little’s law – in steady state, processes leaving queue must equal processes arriving,
thus n = λ x W
-
Valid for any scheduling algorithm and arrival distribution
-
For example, if on average 7 processes arrive per second, and normally 14 processes in queue, then average wait time per process = 2 seconds
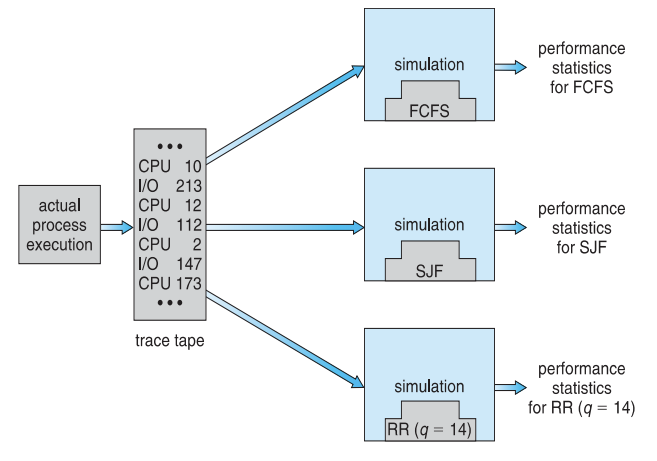
Simulations
가상의 실시간을 소프트웨어로 구현하고, 시뮬레이션 돌리기
- Queueing models limited
- Simulations more accurate
- Programmed model of computer system
- Clock is a variable
- Gather statistics indicating algorithm performance
- Data to drive simulation gathered via
- Random number generator according to probabilities
- Distributions defined mathematically or empirically
- Trace tapes record sequences of real events in real systems
Evaluation of CPU Schedulers by Simulation
Implementation
- Even simulations have limited accuracy
- Just implement new scheduler and test in real systems
- High cost, high risk
- Environments vary
- Most flexible schedulers can be modified per-site or per-system
- Or APIs to modify priorities
- But again environments vary
댓글남기기