
[OS] Memory Management
[toc]
Chapter 9: Memory Management
- Background
- Logical versus Physical Address Space
- Swapping
- Contiguous Memory Allocation
- Paging (시험)
- Segmentation (시험)
- Segmentation with Paging
- Structure of the Page Table
- Example: The Intel 32 and 64-bit Architectures
- Example: ARM Architecture
Objectives
- To provide a detailed description of various ways of organizing memory hardware
- To discuss various memory-management techniques, including paging and segmentation
- To provide a detailed description of the Intel Pentium, which supports both pure segmentation and segmentation with paging
Structure - Top Level
- components are interleaved
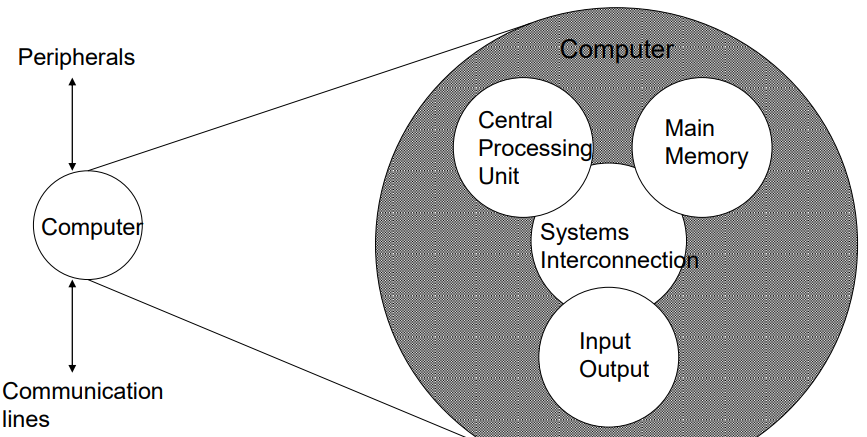
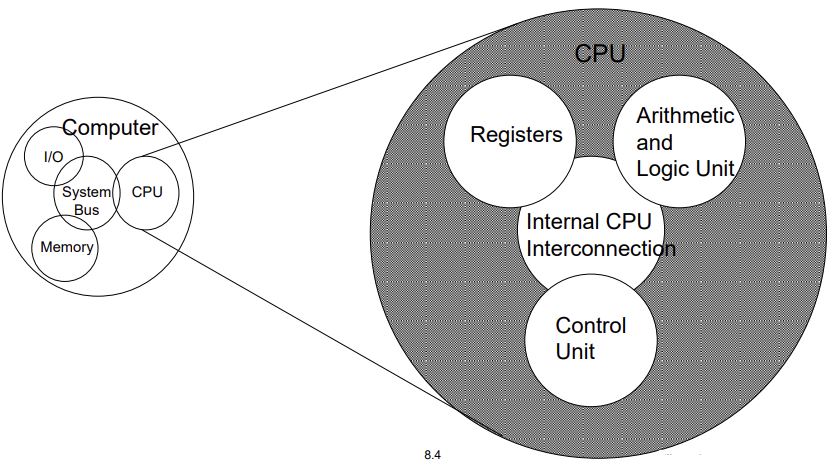
Structure -The CPU
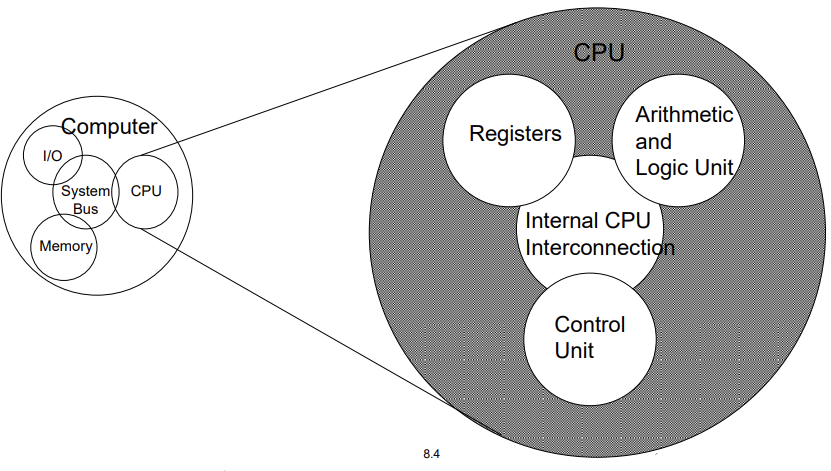
Structure - The Control Unit
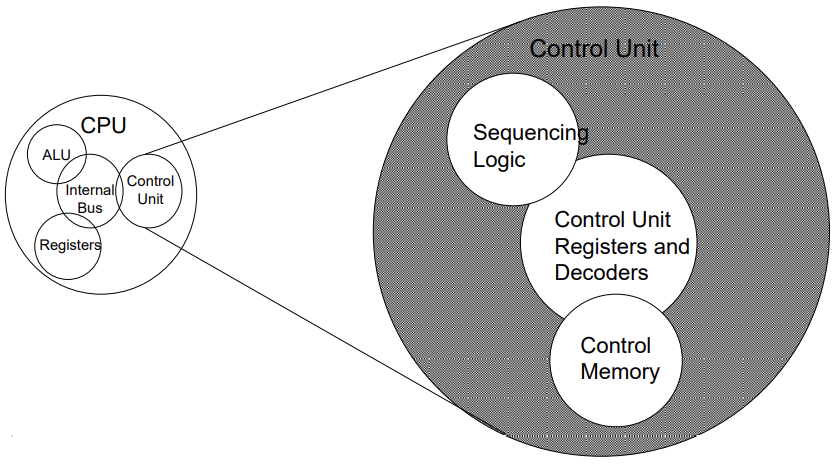
Von Neumann architecture
- Instructions and data are stored in a single read-write memory
- Contents of memory are addressable by location without regard to the type of data contained there
- Execution occurs in sequential fashion unless explicitly modified
- explicitly modified - loop, selection
What is a program?
- A sequence of steps (instructions)
- For each step, an arithmetic or logical operation is done
-
For each operation, a different set of control signals is needed
- instruction cycle의 무한 반복
Instruction Cycle
- Two steps:
- Fetch
- Execute
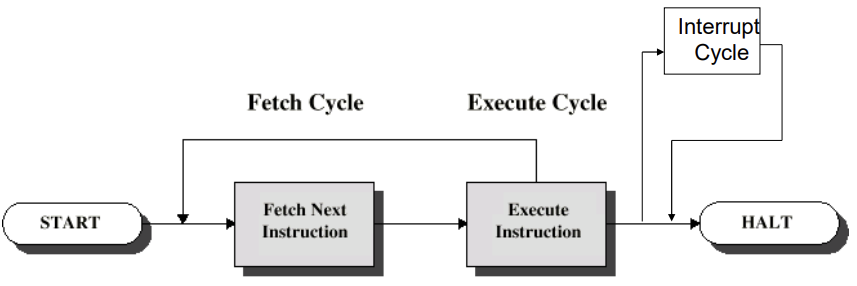
- atomic program
- 외부에서 interrupt를 걸어도 그 즉시 멈추지 않음
- 나중에 처리
Instruction Cycle (with Interrupts) - State Diagram
Background
-
Program must be brought (from disk) into memory and placed within a process for it to be run
-
Main memory and registers are only storage CPU can access directly
-
Memory unit only sees a stream of addresses + read requests, or address + data and write requests
-
Register access in one CPU clock (or less)
-
Main memory can take many cycles, causing a stall
-
Cache sits between main memory and CPU registers
- Protection of memory required to ensure correct operation
- Multi-programming에서의 security
- 여러 프로세스들간에 다른 프로세스의 메모리 영역 침범이 이루어지지 않도록 관리
- Memory resource 관리
- As a result of CPU scheduling -> improved cpu utilization, response
- CPU scheduling과 같이 메모리를 resource 차원에서 관리해야함. (분배 문제)
- A program resides on a disk as a binary executable file -> a.out
- Program must be brought into memory and placed within a process for it to be executed.
- Input queue – collection of processes on the disk that are waiting to be brought into memory for execution.
- Select one of the processes in input queue, load that process into memory (by longterm scheduler)
- Sequence of memory addresses are generated by the running program (Instruction execution cycles, addressing modes)
- If process terminate, its memory space is made available
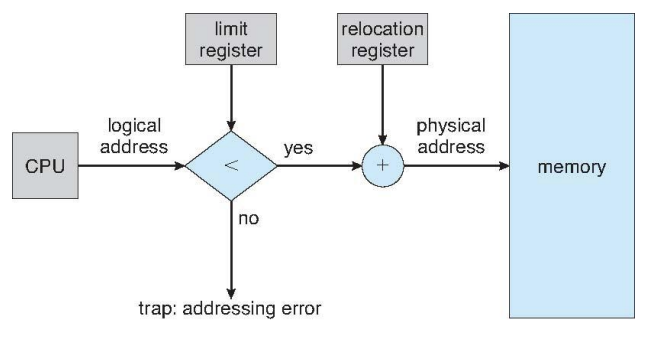
Base and Limit Registers
- A pair of base and limit registers define the logical address space
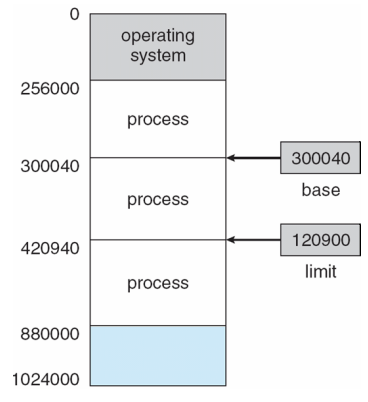
base register - limit register가 가리키는 범주에 벗어난 것은 illegal process로 간주
실행되는 프로세스마다 바뀜 (by OS)
Hardware Address Protection with Base and Limit Registers
- CPU must check every memory access generated in user mode to be sure it is between base and limit for that user
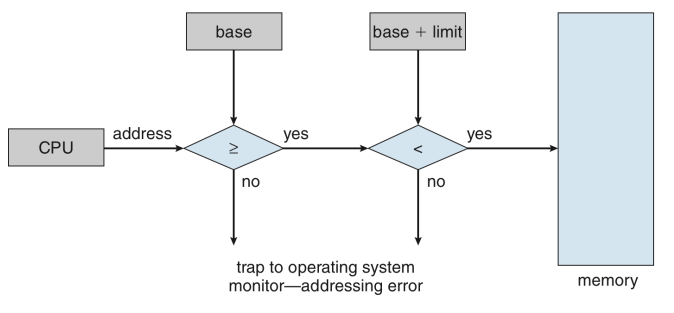
- the instructions to loading the base and limit registers are privileged
Address Binding
- Programs on disk, ready to be brought into memory to execute form an input queue
- Without support, must be loaded into address 0000
- Inconvenient to have first user process physical address always at 0000
- How can it not be?
- Most systems allow a user process to reside in any part of the physical memory
- First address of user process does not need to be 0
- Further, addresses represented in different ways at different stages of a program’s life
Background
- User programs go through several steps before being executed.
- Source code addresses usually symbolic address
- Compiled code addresses bind to
relocatable addresses- A compiler binds symbolic address to relocatable address
- i.e. “14 bytes from beginning of this module”
- Linker or loader will bind relocatable addresses to absolute addresses
- i.e. 74014 - 최종 주소
- Each binding maps one address space to another

- Program
- symbolic address
- 1.c, 2.c
- 1.o, 2.o(by link module)
- relocatable address
- a.out(by linker)
- absolute address
- mm에 탑재(by loader)
Address Binding

- 빈칸으로 되어있는 것은 채우지 못하는 경우
- BLE NEXT가 BLE ___로 되어 있는 이유는 NEXT에 대한 부분의 주소를 아직 모르기 때문에 비워놔야 하는 것이다.
Address Binding
- Internal address(위 예제의 빈칸)는 pass1,2를 통하여 reconcile(조정)됨.
- 소스 코드를 두 번 읽으면 가능
- Reconcile : give actual address
- But, How about addresses which cannot be reconciled at assembly?
- References to external modules
- References to absolute address
Address Binding(안중요)

- What is done at each step ?
- Assembler
- Translate assembly language instruction into machine code
- Format instruction words
- Reconciles labels/variables location
- Usually addresses are generated in relocatable form
- » Assumes first words of program at address zero
- Translate assembly language instruction into machine code
- Assembler
Address Binding(안중요)
- Linker
- Takes various relocatable, assembled modules & combines them into 1 module
- Reconcile external reference
- Generates load module
- What is in load module
- Machine instruction / data
- Information about size of various parts (code, table data)
- Relocation information
- » Addresses which need to be reconciled when module is placed in a particular location in memory
- Takes various relocatable, assembled modules & combines them into 1 module
Address Binding(안중요)
- Loader
- Accepts load module, places it into memory
- Reconciling addresses where necessary
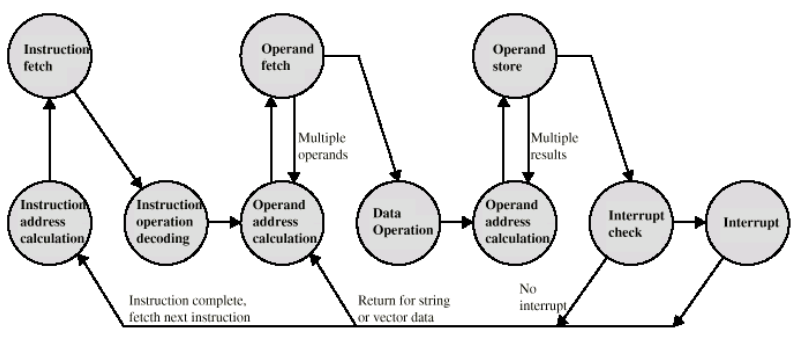
Binding of Instructions and Data to Memory(중요)
Address binding of instructions and data to memory addresses can happen at three different stages.
absolute address가 언제 결정되냐에 따라 다르다! (binding)
- Compile time:
- If it is known at compile time where the process will reside in memory, absolute code can be generated;
- 컴파일 할 때 이 프로그램이 MM에 탑재될 위치의 시작 주소를 알고있을 때 가능
- link module을 만들지 않고 바로 load module을 만듦
- must recompile code if starting location changes.
- If it is known at compile time where the process will reside in memory, absolute code can be generated;
- Load time:
- Must generate relocatable code if memory location is not known at compile time.
- If the starting address changes, we need to reload the user code
- Execution time: (중요)
- Binding delayed until run time if the process can be moved during its execution from one memory segment to another.
- binding이 컴파일을 할 때도 absolute address가 결정되지 않고 loading 할 때도 결정이 안 되고 오직 해당 instruction이 실행될 때만 결정되는 것이다.
- Need hardware support for address maps (e.g., base and limit registers).
Multistep Processing of a User Program
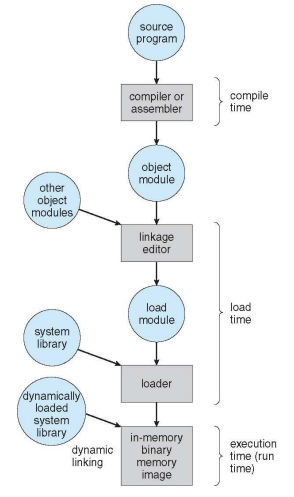
object module - link module
load module(a.out을 만들어냄)
Logical vs. Physical Address Space
- The concept of a logical address space that is bound to a separate physical address space is central to proper memory management.
- Logical address – generated by the CPU; also referred to as virtual address.
- Physical address – address seen by the memory unit.
- MMU : 두 주소 간의 변환을 해주는 역할
- Logical and physical addresses are the same in compile-time and loadtime address-binding schemes; logical (virtual) and physical addresses differ in execution-time address-binding scheme.
- Logical address space is the set of all logical addresses generated by a program
- Physical address space is the set of all physical addresses generated by a program
Physical & Logical storage
- Sharing of memory
- Where is a process information placed?
- How is it later accessed?
- How is security insured?
- Want the addressing to be transparent to user
- Physical storage
- Actual storage in hardware memory of machine, usually start at zero
- Logical storage
- Memory as perceived by process
- Can be larger or smaller than physical storage (같지 않을 수 있음.)
- Size usually limited by architecture (<>virtual address)
- Usually relocatable address
- Memory as perceived by process
- Processes only see logical storage
- Logical address must be translated to physical address
- execution time binding의 경우 변환이 필요!!
- Logical address must be translated to physical address
Memory-Management Unit (MMU)
- Hardware device that at run time maps virtual to physical address
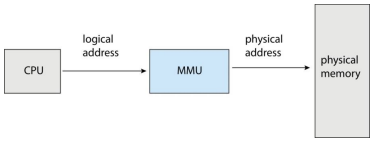
- Many methods possible, covered in the rest of this chapter
- To start, consider simple scheme where the value in the relocation register is added to every address generated by a user process at the time it is sent to memory
- Base register now called relocation register
- MS-DOS on Intel 80x86 used 4 relocation registers
- The user program deals with logical addresses; it never sees the real physical addresses
- logical address만 알아도 physical address에 접근 가능하기 때문에 physical address를 몰라도 됨.
- Execution-time binding occurs when reference is made to location in memory
- Logical address bound to physical addresses
Dynamic relocation using a relocation register
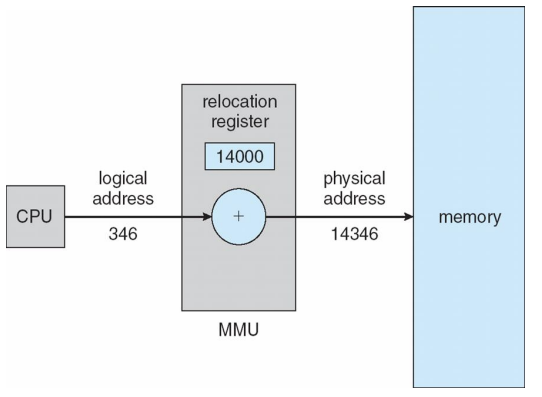
가장 간단한 형태의 주소 변환
Dynamic Loading
- Entire program and data of a process must be in physical memory for the process to execute
- The size of process is limited to the size of physical memory
- To obtain better memory space utilization, dynamic loading can be used
- Routine is not loaded until it is called
- Better memory-space utilization; unused routine is never loaded.
- All routines are kept on disk in a relocatable load format
- When an unloaded routine is needed, relocatable loader is called to load the desired routine into memory, then control is passed to newly loaded code
- Useful when large amounts of code are needed to handle infrequently occurring cases.
- No special support from the operating system is required except providing library routines to implement DL
- implemented through program design.
- OS can help by providing libraries to implement dynamic loading
- 불필요한 루틴의 메모리 탑재 방지
Dynamic Linking
OS가 지원
중복 탑재 방지
- Static linking – system libraries and program code combined by the loader into the binary program image
- shared libraries
- Dynamic linking
- Rather than loading being postponed until execution time, Linking is postponed until execution time.
- Usually used with system libraries such as language library
- W/O this facility, all programs on a system need to have a copy of their language library, wastes both disk and memory
- Small piece of code, stub, is included in the image for each library routine reference
- Stub is used to locate the appropriate memory-resident library routine.
- Stub replaces itself with the address of the routine, and executes the routine
- Operating system checks if routine is in processes’ memory address
- If not in address space, add to address space
- Consider applicability to patching system libraries
- Versioning may be needed
- Need OS support because of address space problem between different processes
Swapping
프로세스 전체 공간을 대상으로
- (MM에 공간이 부족하면) A process can be swapped temporarily out of memory to a backing store, and then(공간에 여유가 생기면) brought back into memory for continued execution
- Total physical memory space of processes can exceed physical memory
- Need execution time binding
- Backing store – fast disk large enough to accommodate copies of all memory images for all users; must provide direct access to these memory images
- Roll out, roll in – swapping variant used for priority-based scheduling algorithms; lower-priority process is swapped out so higher-priority process can be loaded and executed
- Major part of swap time is transfer time; total transfer time is directly proportional to the amount of memory swapped
- System maintains a ready queue of ready-to-run processes which have memory images on disk
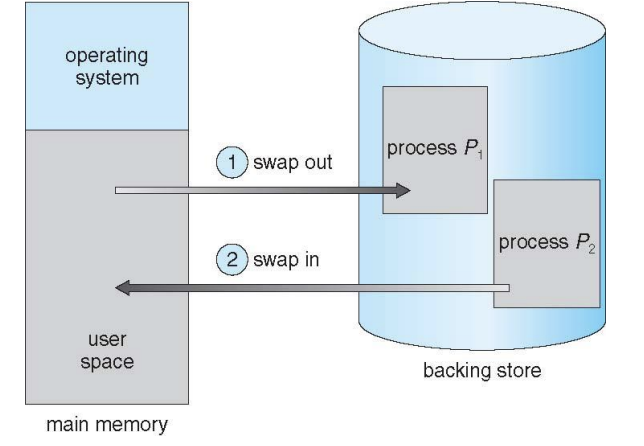
Swapping은 우선순위가 높거나 중요한 프로세스가 메모리에 올라가려 할 때 공간이 부족하면 현재 메모리 위에 올라가 있는 프로세스 중 수많은 알고리즘 중 하나를 이용하여 어떤 프로세스를 잠시 디스크에 저장을 하고 우선순위가 높은 프로세스를 수행하게 되는데요.
이 프로세스가 작업을 마치면 디스크에 있던 프로세스를 다시 메모리에 올리게 됩니다. 이렇게 우선순위가 높거나 중요한 프로세스가 중간에 들어가는 것을 Swap-in이라 하며 자리를 내어주어 디스크로 빠지게 되는 과정을 Swap-out이라고 합니다.
Swap-out 된 프로세스가 다시 메모리에 올라갈 때는 원래 있던 자리로 돌아가지 않을 수 있습니다. 여기서 수많은 알고리즘 중 상황에 맞는 알고리즘을 고르는 것과 디스크와 메모리 간의 속도 차로 인해 발생하는 이슈들이 존재합니다.
Swapping
- Does the swapped out process need to swap back in to same physical addresses?
- No!!!!!!!!!!
- Depends on address binding method
- Plus consider pending I/O to / from process memory space
- Modified versions of swapping are found on many systems (i.e., UNIX, Linux, and Windows)
- Swapping normally disabled
- Started if more than threshold amount of memory allocated
- Disabled again once memory demand reduced below threshold
Schematic View of Swapping
Context Switch Time including Swapping
- If next processes to be put on CPU is not in memory, need to swap out a process and swap in target process
- Context switch time can then be very high
- 100MB process swapping to hard disk with transfer rate of 50MB/sec
- Plus disk latency of 8 ms
- Swap out time of 2008 ms
- Plus swap in of same sized process
- Total context switch swapping component time of 4016ms (> 4 seconds)
- Can reduce if reduce size of memory swapped – by knowing how much memory really being used
- System calls to inform OS of memory use via request memory and release memory
- request_memory() and release_memory()
Context Switch Time including Swapping
- Other constraints as well on swapping
- Pending I/O – can’t swap out as I/O would occur to wrong process
- Or always transfer I/O to kernel space, then to I/O device
- Known as double buffering, adds overhead
- kernel space의 buffer에서 user space의 buffer로 또 다시 buffering을 해야 함.
- Known as double buffering, adds overhead
- Standard swapping not used in modern operating systems
- But modified version common
- Swap only when free memory extremely low
- But modified version common
Swapping on Mobile Systems
- Not typically supported
- Flash memory based
- Small amount of space
- Limited number of write cycles
- Poor throughput between flash memory and CPU on mobile platform
- Flash memory based
- Instead use other methods to free memory if low
- iOS asks apps to voluntarily relinquish allocated memory (할당 받은 메모리 반납 요청)
- Read-only data thrown out and reloaded from flash if needed
- Failure to free can result in termination
- Android terminates apps if low free memory, but first writes application state to flash for fast restart
- Both OSes support paging as discussed below
- iOS asks apps to voluntarily relinquish allocated memory (할당 받은 메모리 반납 요청)
Memory management
- How memory is allocated to different jobs to hold their (entire or parts of) load module
- Various levels of memory
- Cache, main memory, secondary storage
- Access slower storage (secondary storage) as infrequently as possible
- When need to access?
- Fetch instruction
- Fetch data/store data
- Use of main memory
- Utilize to fullest
- Must be shared
- Various levels of memory
Placement of modules in memory
- Main memory must support both OS and user processes
- Kernel remains in main memory
- Memory have security (between kernel and user, between users)
- Limited resource, must allocate efficiently
- Determine different placement strategies for user processes
- Compare strategies based on
- Internal fragmentation
- block의 단위 할당으로 인해 요청하는 메모리 크기보다 큰 메모리를 할당해 주어 메모리 낭비가 일어나는 것
- Pieces of memory which are associated with a process but which the process cannot using
- This space cannot be allocated
- External fragmentation
- 메모리 공간을 연속적으로 할당해서 생기는 문제
- 메모리 공간 50이 남아있을 때 40을 요청해도 조각조각 나있으면 줄 수가 없다.
- Pieces of free too small to be allocated and are therefore wasted
- free space이긴 하지만 너무 작아서 다른 것에게 할당할 수 없는 공간
- 두가지 fragmentation을 최소화 시켜야 함.
- Internal fragmentation
- Degree of multi-programming
- 몇개의 프로그램이 동시에 실행 중인가
- Measure of number of jobs which can be in system based on the allocation of some portion of memory for the job’s use
Contiguous Allocation
- Main memory usually into two partitions:
- Resident operating system, usually held in low memory with interrupt vector.
- User processes then held in high memory.
- Each process contained in single contiguous section of memory
- Relocation registers used to protect user processes from each other, and from changing operating-system code and data
- Base register contains value of smallest physical address
- Limit register contains range of logical addresses – each logical address must be less than the limit register
- MMU maps logical address dynamically
- Can then allow actions such as kernel code being transient and kernel changing size
Hardware Support for Relocation and Limit Registers
Single-partition allocation
- Single job in memory (All or nothing)
- Place the entire job in the user portion main memory
- Where is job placed?
- User job can be at address directly next to kernel space
- Kernel-user or user-kernel depending on interrupt h/w
- Relocation-register scheme used to protect user processes from each other, and from changing operating-system code and data.
- Relocation register contains value of smallest physical address; limit register contains range of logical addresses – each logical address must be less than the limit register.
- Adv.: Compile time address binding
- Dis, : need recompiling when kernel size changes
- Kernel routine 중 자주 수행되지 않는 program을 불러들일때
- Place user job at opposite end of memory and allow to grow toward kernel space
- Translation of logical to physical (execution time biding)
- Security
- Simple addressing
- Kernel routine 중 자주 수행되지 않는 program을 불러들일때
Multiple fixed parition
- MM is divided into a number of fixed size partition
- When a process arrives, it is placed into one of the partition which are larger than job itself -> process is assigned entire partition
- Prob.
- internal fragmentation
- Degree of multiprogramming bounded by # of partitions
- Advantages
- Address change easy, because simple addressing
- Easy security
- Easy bookeeping : no free memory management
- What if a job does not fit the partition/memory ? (larger than)
- overlay
Overlays(생략)
- Keep in memory only those instructions and data that are needed at any given time.
- Breaks program into pieces (Fig. 8.2)
- When other instructions are needed, they are loaded into space that are occupied by instructions that are no longer needed
- Needed when process is larger than amount of memory allocated to it.
- Implemented by user, no special support needed from operating system, programming design of overlay structure is complex
Multiple - Variable sized partition allocation
- Multiple-partition allocation
- Degree of multiprogramming limited by number of partitions
- Variable-partition sizes for efficiency (sized to a given process’ needs)
- Hole – block of available memory; holes of various size are scattered throughout memory.
- 연속적으로 메모리를 할당해주면 프로세스마다 할당된 메모리 공간 사이에 할당 되지 않은 빈공간이 생기게 되는데 이를 hole 이라고 한다.
- When a process arrives, it is allocated memory from a hole large enough to accommodate it.
- Process exiting frees its partition, adjacent free partitions combined
- Operating system maintains information about: a) allocated partitions b) free partitions (hole)
- Non internal, external Fragmentation
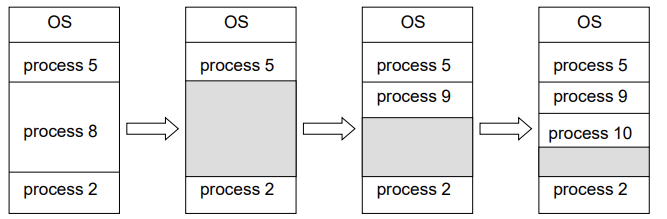
Dynamic Storage-Allocation Problem
How to satisfy a request of size n from a list of free holes.
연속된 메모리 공간을 할당해 주는 방법에 크게 세가지 내부적은 방법이 존재한다.
- First-fit: Allocate the first hole that is big enough.
- 메모리 요청이 들어왔을 때 요청한 크기를 만족하는 hole 중 가장 첫 번째 hole을 할당
- Maintain free space information as a linked list sorted by address (start, size)to allocate search list, assign first partition whose size is larger than job
- On fly compaction
- Ability to combine adjacent free space
- Easy to maintain list in order
- Long search time
- External fragmentation
- Decreases size of large block
- Potentially increase search time
- Best-fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size. Produces the smallest leftover hole.
- 메모리 요청이 들어왔을 때, 요청한 크기를 만족하는 hole 중 가장 작은 크기의 hole을 할당
- Maintain free space as large of chunks as possible
- Maintain list is sorted in increasing size order
- Elements may have to be moved in the list when they change in size
- Remainder is going to be smaller
- Worst-fit: Allocate the largest hole; must also search entire list. Produces the largest leftover hole.
- Best-Fit과 반대로 요청한 크기를 만족하는 Hole 중 가장 큰 크기의 Hole을 할당
- Maintain list in decreasing size order
- Try to avoid generating small pieces of free space
- Decrease the amount of large free space
- First-fit and best-fit better than worst-fit in terms of speed and storage utilization
- First fit analysis reveals that given N blocks allocated, 0.5 N blocks lost to fragmentation
- 1/3 may be unusable -> 50-percent rule
- internal fragmentation 발생!!
Fragmentation - 중요
- External fragmentation – total memory space exists to satisfy a request, but it is not contiguous.
- Internal fragmentation – allocated memory may be slightly larger than requested memory; this size difference is memory internal to a partition, but not being used.
- Reduce external fragmentation by compaction (따닥따닥 붙여서!)
- Shuffle memory contents to place all free memory together in one large block.
- Compaction is possible only if relocation is dynamic, and is done at execution time.
- 할당된 메모리 공간들을 한쪽으로 모아 연속된 공간을 확보하는 것
- I/O problem
- Latch job in memory while it is involved in I/O.
- Do I/O only into OS buffers.
- 하지만 이러한 방법들은 실행 시간에 주소 바인딩이 일어나는 프로그램들만 가능하며 그렇지 않은 경우 압축되었을 때 잘못된 메모리 공간의 주소에 접근하게 될 수 있다. -> 상당히 제한적임
- Now consider that backing store has same fragmentation problems
그래서 나온 방식이 애초에 메모리 공간을 연속하지 않게 할당해 주는 방법이다.
- 하나는 Paging 기법
- 하나는 Segmentation 기법
Segmentation
-
Memory-management scheme that supports user view of memory
-
A program is a collection of segments
-
A segment is a logical unit such as:
main program
procedure
function
method
object
local variables, global variables
common block
stack
symbol tablearray
-
- Paging 기법은 Logical address를 page 단위로, physical address 를 같은 크기의 frame 단위로 나누어 올리고 접근
- Segmentation은 모두 고정된 크기가 아니라 일련의 논리적 구조 단위(logical unit)로 나누어 진다.
- 이렇게 논리적 단위로 나누면 사용자가 메모리의 상태를 이해하는데 더욱 도움이 된다.
User’s View of a Program
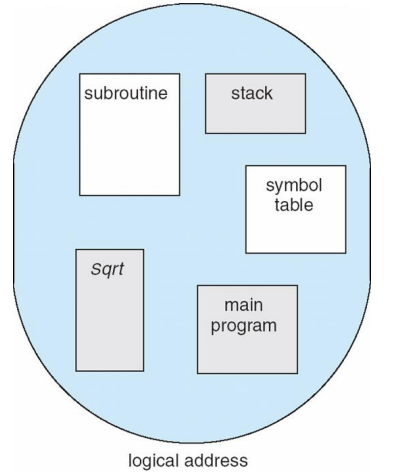
사용자 프로그램은 logical segmentation으로 구성
Logical View of Segmentation
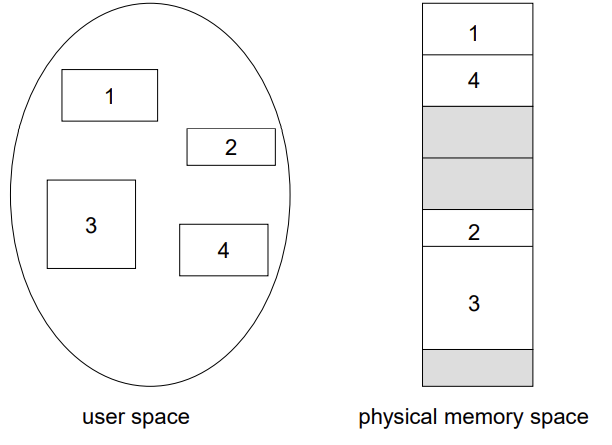
사용자 프로세스(4개)가 메모리에 탑재 될 때 segment 별로 탑재 되기 때문에 비연속적인 공간에 할당된다.
- 순서도 맞지 않음
Segmentation Architecture
-
Logical address consists of a two tuple:
<segment-number, offset>
-
Segment table – maps two-dimensional physical addresses; each table entry has:
-
base – contains the starting physical address where the segments reside in memory
-
limit – specifies the length of the segment
-
-
Segment-table base register (STBR) points to the segment table’s location in memory
-
Segment-table length register (STLR) indicates number of segments used by a program;
segment number s is legal if s < STLR
-
paging은 모두 같은 크기이기 때문에 따로 크기에 대한 정보를 갖고 있지 않지만, segmentation은 크기가 제각기 다 다르기 때문에 크기를 알기 위해 해당 segmentation의 시작점을 알리는 base 정보와 끝을 알리는 limit을 갖고 있는다.
Segmentation Architecture (Cont.)
- Protection
- With each entry in segment table associate:
- validation bit = 0 -> illegal segment
- read/write/execute privileges
- With each entry in segment table associate:
-
Protection bits associated with segments; code sharing occurs at segment level
-
Since segments vary in length, memory allocation is a dynamic storage-allocation problem
-
A segmentation example is shown in the following diagram
- Relocation.
- dynamic
- by segment table
- Sharing.
- shared segments
- same segment number : self reference
- Allocation.
- first fit/best fit
- external fragmentation
Segmentation Hardware
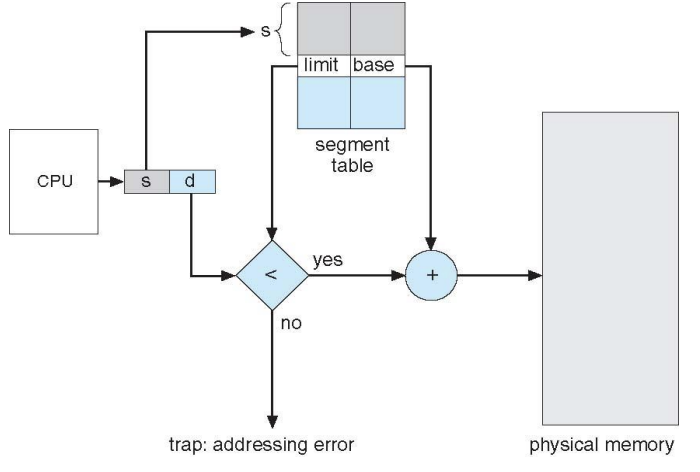
-
CPU를 출발하는 주소 - logical address
-
segment 번호
-
displacement
-
-
segmentation table에 접근하는 S값에 대해서 먼저 limit를 초과하는지에 대한 검사를 통해 잘못된 주소 접근을 막는다.
Example of Segmentation
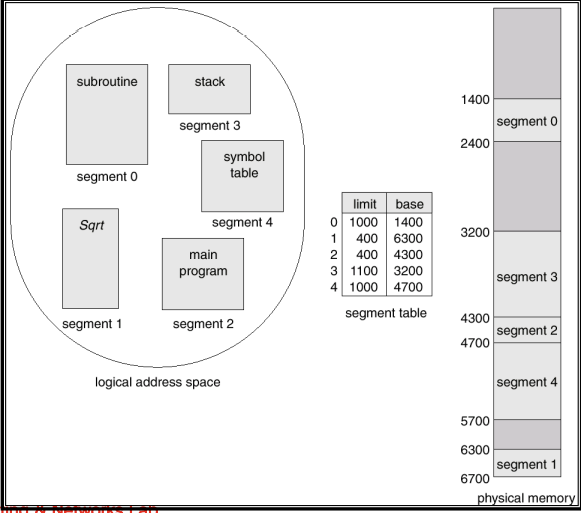
- segmentation은 고정된 크기로 나누어 지지 않는 다는 점을 제외하고 paging 기법과 상당히 유사한 점이 많다.
Sharing of segments
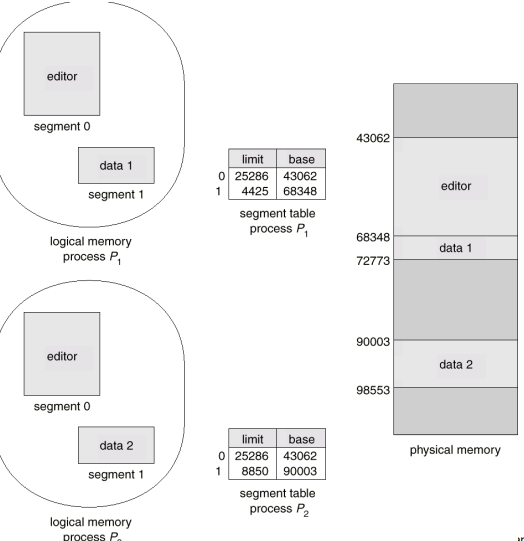
- code section은 segment table 정보(base+limit)를 동일하게 하면 공유가 가능!
- segmentation 역시 paging과 마찬가지로 공통된 부분은 한 번씩만 올리고 그 주소를 같이 공유하는 shared code를 지원한다.
Paging
segmentation과의 차이는 단위임.
-
앞서 언급했듯이 프로세스에게 메모리를 연속적으로 할당해 주지 않기 위해 나온 방법이다.
- Another solution to external fragmentation
- Physical address space of a process can be noncontiguous; process is allocated physical memory whenever the latter is available.
- Avoids external fragmentation
- Avoids problem of varying sized memory chunks
- Divide physical memory into fixed-sized blocks called frames (size is power of 2, between 512 bytes and 8192 bytes).
- Divide logical memory into blocks of same size called pages.
- Keep track of all free frames.
- To run a program of size n pages, need to find n free frames and load program.
- n page 크기의 프로그램을 실행하기 위해서 n개의 남는 frame을 찾고 프로그램을 로딩한다.
- Set up a page table to translate logical to physical addresses.
- Backing store likewise split into pages
- Still have Internal fragmentation, External?
- internal fragmentation 제거 불가능
- 할당의 기본단위가 frame이기 때문에 1바이트를 위해서도 반드시 한 개의 frame을 할당받아야 한다.
- external fragmentation 제거 가능
- internal fragmentation 제거 불가능
Address Translation Scheme
이러한 paging 기법은 메모리의 연속적인 공간에 올라가지 않기 때문에 각각이 어느 위치에 올라가는지 Page Table에 저장된 값으로 주소를 변환하여 원하는 위치에 접근해야 한다.
-
Address generated by CPU is divided into:
- Page number (p) – used as an index into a page table which contains base address of each page in physical memory
- Page offset (d) – combined with base address to define the physical memory address that is sent to the memory unit
-

- For given logical address space 2m and page size 2n
Address Translation Scheme
- Address generated by CPU is divided into:
- Page number (p) – used as an index into a page table which contains base address of each page in physical memory.
- Page offset (d) – combined with base address to define the physical memory address that is sent to the memory unit.
- Given page size P under logical address A
- p = A div P
- d = A mod P
- Ex) page size = 10 , logical address = 31
- P = 31 div 10 = 3
- D = 31 mod 10 = 1
| 3 | 1 |
Paging Hardware
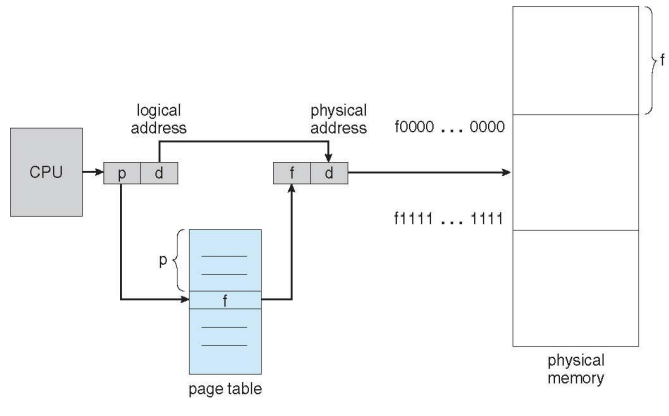
Paging Model of Logical and Physical Memory
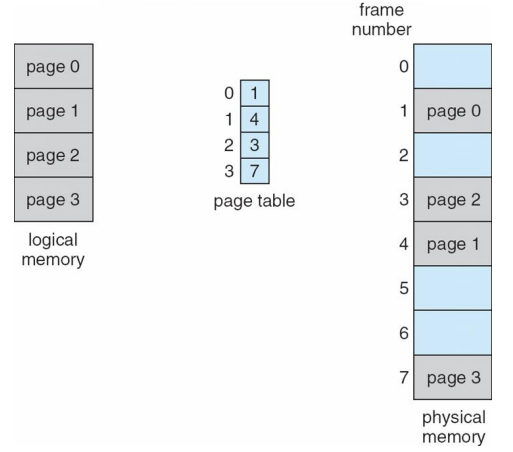
compile time binding이나 load time binding은 이런 과정이 필요없음
- logical address = physical address이기 때문에
Paging Example
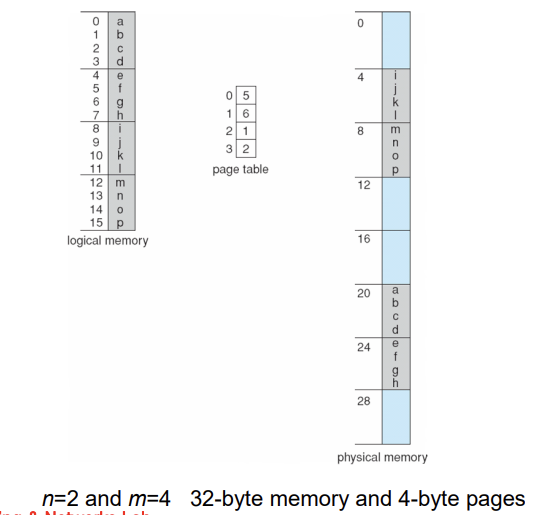
Paging (Cont.)
- Calculating internal fragmentation
- Page size = 2,048 bytes
- Process size = 72,766 bytes
- 35 pages + 1,086 bytes
- Internal fragmentation of 2,048 - 1,086 = 962 bytes
- Worst case fragmentation = 1 frame – 1 byte
- On average fragmentation = 1 / 2 frame size
- So small frame sizes desirable?
- But each page table entry takes memory to track
- Page sizes growing over time
- Solaris supports two page sizes – 8 KB and 4 MB
- Process view and physical memory now very different
- By implementation process can only access its own memory
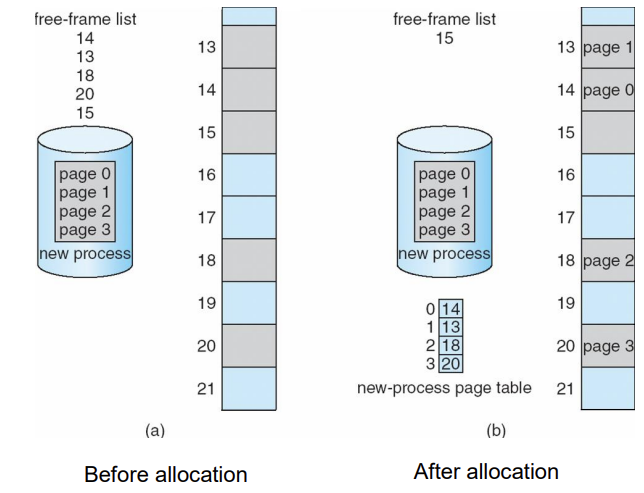
Free Frames
Implementation of Page Table
- Pages can be mapped into non-contiguous frames
- Page table is kept in main memory.
- page table을 사용하기 위해서는 page table 역시 main memory에 올라가 있어야 하는데, 이 때 PTBR은 page table의 메모리 위에서의 시작지점을 의미하고 PTLR은 page table의 크기를 나타낸다.
- 이 두 값으로 잘못된 주소 접근을 방지한다.
- Page-table base register (PTBR) points to the page table
- 빨리 찾아가기 위함
- Page-table length register (PTLR) indicates size of the page table
- Rarely does a process use all its address range
- entry 갯수를 줄이기 위함
- In this scheme every data/instruction access requires two memory accesses( -> 성능 저하).
One for the page table and one for the data/instruction.
- page table을 보기 위해서 메모리에 접근해서 생기는 문제!
- The two memory access problem can be solved by the use of a special fastlookup hardware cache called associative memory or translation lookaside buffers (TLBs)
- page table이 memory에 올라가 있기 때문에 data나 instruction에 접근하기 위해서는 두 번의 메모리 access가 일어나는데
- 하나의 데이터나 명령문에 접근하기 위해 메모리에 여러번 access 하는 건 비효율 적이기 때문에 그래서 나온 것이 Translation Look-aside Buffer(TLB)이다.
- Some TLBs(Translation Lookaside Buffer) store address-space identifiers (ASIDs) in each TLB entry
- uniquely identifies each process to provide address-space protection for that process
- (context switching 시에)Otherwise need to flush at every context switch
- uniquely identifies each process to provide address-space protection for that process
- TLBs typically small (64 to 1,024 entries)
- On a TLB miss, value is loaded into the TLB for faster access next time
- Replacement policies must be considered
- Some entries can be wired down for permanent fast access
- TLB hit면 MM에 접근하지 않아도 됨.
Associative Register
TLB는 일종의 캐시 역할을 하는 레지스터로 역할이 비슷핟.ㅏ
메모리에 여러번 access 하는 걸 막고자 page table의 내용을 TLB에 저장하여 바로 메모리에 접근할 수 있게 한다.
-
시작은 비어있는 TLB로 page table을 통해 메모리를 두 번 access를 반드시 해야하지만 한 번 access 되기만 한다면 그 다음부터는 해당 page table 정보가 TLB에 저장이 되어 이것을 통해 바로 memory에 access 하는 것이 가능해 진다.
-
Associative registers – parallel search
- Address translation (p, d)
- If p is in associative register, get frame # out.
- Otherwise get frame # from page table in memory
- ASID가 같이 저장될 수 있음
Paging Hardware With TLB
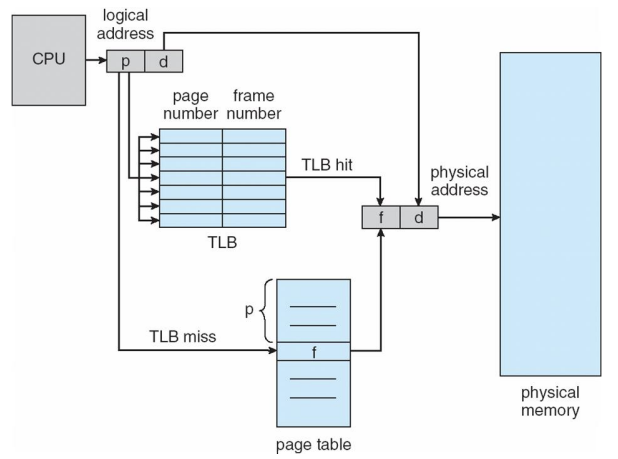
TLB hit의 overhead - TLB cache에서 searching time («« MM access time)
TLB Miss의 overhead - TLB searching time + page table searching time + MM access time
Effective Access Time
-
Associative Lookup = ε time unit
- Can be < 10% of memory access time
-
(TLB) Hit ratio = α
- Hit ratio – percentage of times that a page number is found in the associative registers; ratio related to number of associative registers
-
Consider α = 80%, ε = 20ns for TLB search, 100ns for memory access Assume memory cycle time is 1 microsecond
-
Effective Access Time (EAT)
EAT = (1 + ε) α + (2 + ε)(1 – α)
= 2 + ε – α
- (1 + ε) α ->
- TLB Hit : TLB seach = 1 + ε (한번의 memory access)
- (2 + ε)(1 – α) ->
- TLB Miss: TLB search + page table search + physical m.m search = 2 + ε (2번의 memory access)
- (1 + ε) α ->
-
Consider α = 80%, ε = 20ns for TLB search, 100ns for memory access
- EAT = 0.80 x 120 + 0.20 x 220 = 140ns
-
Consider slower memory but better hit ratio -> α = 98%, ε = 20ns for TLB search, 140ns for memory access
- EAT = 0.98 x 160 + 0.02 x 300 = 162.8ns
Memory Protection
page 단위 protection (by validation bit)
- Memory protection implemented by associating protection bit with each frame to indicate if read-only or read-write access is allowed
- Read only, read-write, execution only bits
- Valid-invalid bit attached to each entry in the page table:
- “valid” indicates that the associated page is in the process’ logical address space, and is thus a legal page
- “invalid” indicates that the page is not in the process’ logical address space
- Or use PTLR
- Page-table length register (PRLR) indicates size of the page table.
- Rarely does a process use all its address range
- Any violations(trap) result in a trap to the kernel
Valid (v) or Invalid(i) Bit In A Page Table
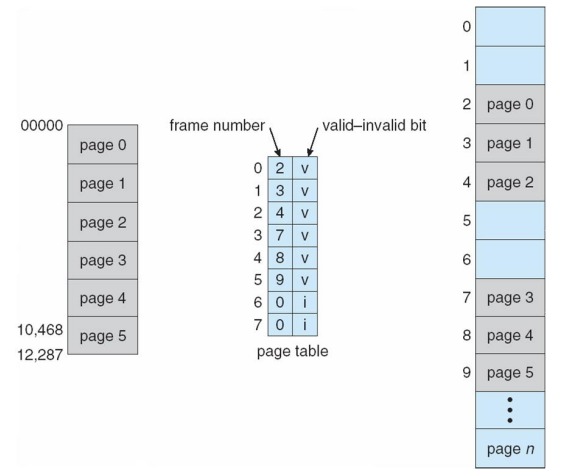
- Logical memory가 page 단위로 나누어져 있는 모습을 가장 왼쪽 그림을 보면 알 수 있는데 이 경우 internal fragmentation이 발생할 수밖에 없다.
- 하지만 internal fragmentation되어 비어 있는 공간의 주소를 접근하는 것은 반드시 막아야 하기 때문에 valid-invalid Bit를 사용하게 된다.
- v - 허용된 범위의 page table
- i - 실제로 프로세스가 가리킬 수 있는 주소 공간 안에 포함 된 듯 하지만 실제로는 사용하지 않는 page
Shared Pages
- 공통된 code를 갖는 여러 프로세스들이 page table을 가질 때 중복이 발생하게 되는데 아무래도 공통된 code를 공유하는 것이기 때문에 page table 역시 같은 부분이 존재하게 된다.
-
이런 경우 공통된 page table을 한 번만 메모리에 올리고 그것에 대한 주소를 서로 다른 프로세스들이 공유하면서 중복된 page table을 공유하며 메모리 공간의 낭비를 막는다.
- Shared code
- One copy of read-only (reentrant; 값이 바뀌지 않는, 재진입 가능한) code shared among processes (i.e., text editors, compilers, window systems)
- Similar to multiple threads sharing the same process space
- Also useful for interprocess communication(IPC) if sharing of read-write pages is allowed
- Private code and data
- Each process keeps a separate copy of the code and data
- The pages for the private code and data can appear anywhere in the logical address space
Shared Page Examples
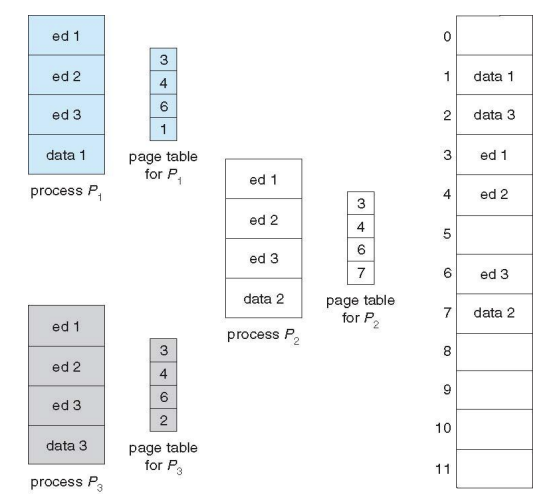
- ed1~3: read only
- 공유하기 때문에 같은 곳을 가리켜서 접근
Structure of the Page Table
- 두 가지 문제점
- 성능
- 메모리 - 메인메모리에 존재하기 때문에 어찌됐건 메인 메모리의 공간을 차지함.
- Memory structures for paging can get huge using straight-forward methods
- Consider a 32-bit logical address space as on modern computers
- Page size of 4 KB (212)
- Page table would have 1 million entries (232 / 212)
- If each entry is 4 bytes -> 4 MB of physical address space / memory for page table alone
- 프로세스 하나당 4MB
- That amount of memory used to cost a lot
- Don’t want to allocate that contiguously in main memory
- Hierarchical Paging
- Hashed Page Tables
- Inverted Page Tables
Hierarchical Page Tables
- Break up the logical address space into multiple page tables
- 하나의 페이지 테이블 안에 여러개의 페이지 테이블을 넣은 페이지 테이블을 의미한다.
- A simple technique is a two-level page table
-
We then page the page table
- 사용자 프로세스의 logical address 공간을 paging 하는 것이 paging의 목적인데 여기서는(Hierarchical Page Tables) 사용자 프로세스를 지원하는 page table 자체를 또 다시 paging
- 용량을 줄이는 것이 목적이 아님!
Two-Level Page-Table Scheme
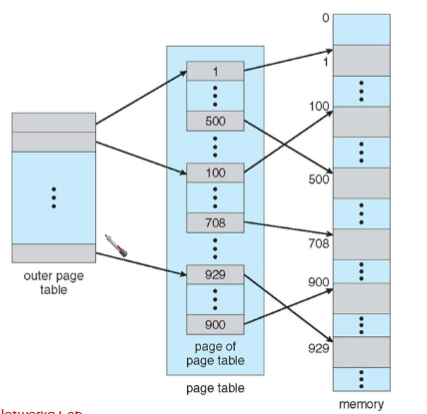
-
outer page table에 의해 mapping이 되기 때문에 page table에서 page들은 비연속적으로 깔려도 됨.
- 한 page가 1024개의 entry를 갖고 있음
- original page table
- 4KB 짜리 page 1024개
- original page table에서는 위 그림의 page table안에 있는 것들이 하나로 묶여 있었음.(continusouly)
- Two-level page table
- original page table에서 어떤 page인지 구분하기 위해서 outer page table 하나를 더 두어서 사용하기 때문에 4KB가 더 추가되었음.
- outer page table에 의해서 mapping이 되기 때문에 page가 비연속적으로 깔려도 된다!!!
Two-Level Paging Example
- A logical address (on 32-bit machine with 4K page size) is divided into:
- a page number consisting of 20 bits
- a page offset consisting of 12 bits.
- Since the page table is paged, the page number is further divided into:
- a 10-bit page number.
- a 10-bit page offset.
- Thus, a logical address is as follows:

-
single level page P가 p1, p2로 나눠짐
-
p1을 통해서 outer-page table의 index를 찾고 해당 index가 가리키는 page table entry 중 하나에서 p2를 통해 physical memory의 frame 번호를 찾는다. 마지막으로 d를 통해 physical 메모리에서의 위치를 찾는다.
- where p1 is an index into the outer page table, and p2 is the displacement within the page of the outer page table.
- page entry 하나를 표현하는데 4byte, 하나의 page는 4KB
- -> 한 페이지가 수용할 수 있는 page entry의 갯수는 1K = 1000개
- -> 그래서 p2에 10bit가 할당 되어야지 1024까지 표현할 수 있음(210)
- page entry 하나를 표현하는데 4byte, 하나의 page는 4KB
-
Known as forward-mapped page table
- page table size / page table entry 한 개의 size = 한 페이지가 포함할 수 있는 page table entry 최대 갯수
- 한 page가 1024개의 entry를 갖고 있기 때문에 p2 = 10 bit
Address-Translation Scheme
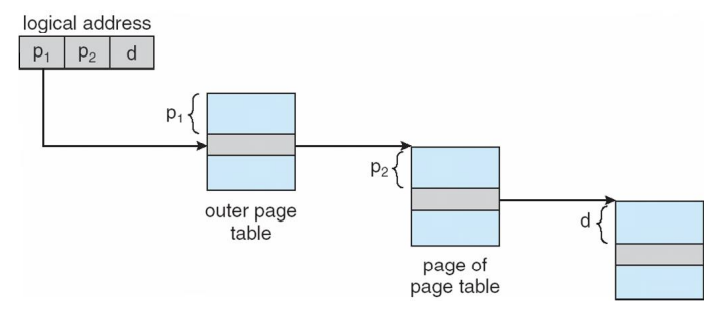
- outer page table에서 하나의 inner page table을 가리키게 되는데 inner page table은 page table 안에 1024개가 있고 각 inner page table마다 page entry가 1024개가 있다.
- 그리고 각 page entry 마다는 4KB이다.
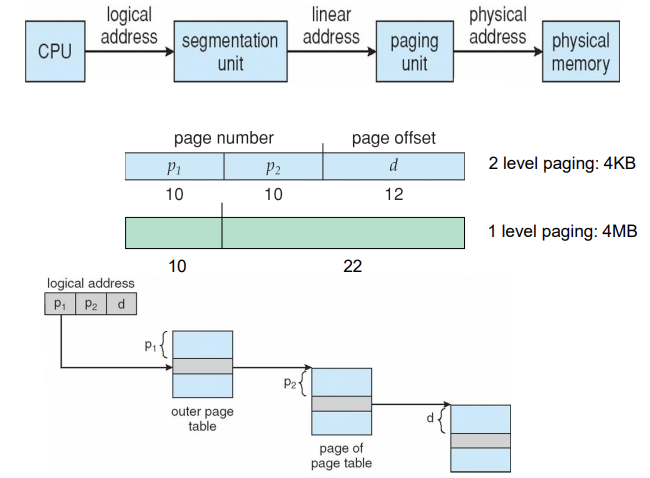
Multilevel Paging(64-bit Logical Address Space)
-
64bit
-
If page size is 4 KB (212)
-
Then page table has 252 entries
-
If we use 2-level paging scheme, inner page tables could be 1 page long (210 4 byte entries)
-
Address would look like

-
Outer page table has 242 entries or 244 bytes
- outer page table이 너무 커지는데…?(심지어 연속적인 공간에 깔려야 함.)
- One solution is to add a 2nd outer page table (Three level paging scheme)
- outer page table이 너무 커지는데…?(심지어 연속적인 공간에 깔려야 함.)
-
But in the following example the 2nd outer page table is still 234 bytes in size
- And possibly 4 memory access (three level page + page offset) to get to one physical memory location
-
Three-level Paging Scheme
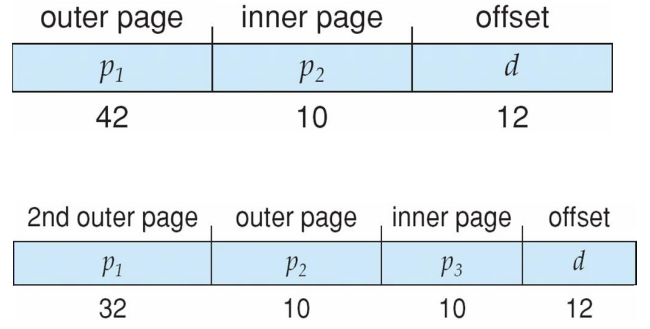
Four level paging scheme
-
Since each level is stored as a separate table in memory, covering a logical address to a physical one may take four memory accesses. (p1,p2,p3,p4,d)
- -> 32bit가 여전히 부담 스러워서
-
Even though time needed for one memory access is quintupled, caching permits performance to remain reasonable.
-
Cache hit rate of 98 percent yields:
effective access time = (0.98 x 120) + (0.02 x 520)
= 128 nanoseconds.
- 520: 5번의 access(500?) + TLB cache 검색 시간(20)
- 5번의 memory access -> 4 level page + page offset(actual page access)
- 520: 5번의 access(500?) + TLB cache 검색 시간(20)
which is only a 28 percent slowdown in memory access time.
Hashed Page Tables
- A Common approach in case of address spaces > 32 bits.
- 주로 주소 공간이 32bit보다 큰 경우 사용한다.
- The virtual page number is hashed into a page table.
- VPN이 hash function의 key로 사용
- 해시형 테이블의 각 항목은 linked list를 갖고 있다.
- This page table contains a chain of elements hashing to the same location.
- Each element contains (1) the virtual page number(q) (2) the value of the mapped page frame(s) (3) a pointer to the next element
- Virtual page numbers are compared in this chain searching for a match.
- If a match is found, the corresponding physical frame is extracted.
- Variation for 64-bit addresses is clustered page tables
- Similar to hashed but each entry refers to several pages (such as 16) rather than 1
- 한 개의 페이지 테이블 항목이 여러 페이지 프레임에 대한 매핑 정보를 지닐 수 있다.
- Especially useful for sparse address spaces (where memory references are non-contiguous and scattered)
Hashed Page Table
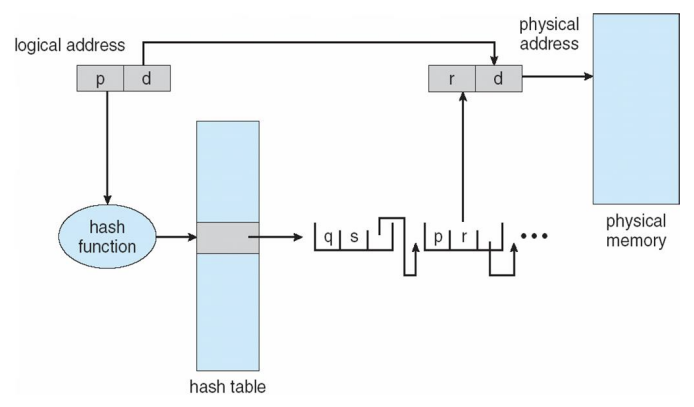
- 서로 다른 p값에 대해 동일한 hash 값이 얻어지게 되면 오또케? -> collision 발생
- 동의어(Synonym) : 충돌이 일어난 레코드의 집합. 키값이 같은 레코드의 집합으로, 동의어가 슬롯의 갯수보다 많으면 오버플로우가 일어날 수 있다.
- hash function에 의해 얻어지는 값이 unique 하면 hash table에 저장, 삽입
- O(1)
- collision을 해결하기 위한 방법으로는 linked list를 활용해서 중복 값이 나오면 linked list로 쭉쭉 연결해 나가서 p값, 즉 page number가 내가 찾는 page number인지를 확인하여 찾는 방법이 있다.
- O(n)
- hash table을 통해 linked list로 이어지기 때문에 이 역시 비연속적인 탑재가 가능하다.
Inverted Page Table
- 메모리 프레임마다 한 항목씩을 할당한다.
- 각 항목은 프레임에 올라와 있는 페이지 주소, 그 페이지를 소유하고 있는 pid를 표시한다.
- 따라서 그 시스템에는 단 하나의 페이지 테이블만 존재하게 되어 공간을 절약할 수 있게 된다.
- Each process has a page table associated with it
- Each page table may consists of millions of entries
- Rather than each process having a page table and keeping track of all possible logical pages, track all physical pages
- One entry for each real page (frame) of memory.
- Entry consists of the virtual address of the page stored in that real memory location, with information about the process that owns that page.
- Decreases memory needed to store each page table, but increases time needed to search the table when a page reference occurs.
- whole table might be searched
- Use hash table to limit the search to one — or at most a few — page-table entries.
- TLB can accelerate access (Associated memory register)
- But how to implement shared memory?
- One mapping of a virtual address to the shared physical address
Inverted Page Table Architecture
- each virtual address consists of <process-id, page-number, offset>
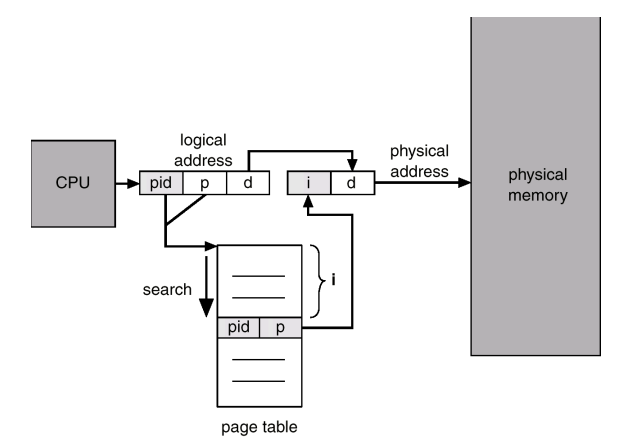
- 시스템에 page table이 딱 하나만 존재
- page table 탑재에 필요한 main memory 용량을 줄이는 효과를 볼 수 있음
- pid + p 가 일치하는 index를 찾는다.
- physical memory에 enry가 100개 있으면 page table도 100개가 있음
-
가상 주소는 <pid, page number, offset> 으로 구성된다.
-
메모리 참조가 발생하면 page table에 가서 <pid, page number>가 일치하는 항목을 찾는다.
-
일치하는 것이 i번째 항목에서 발견되면 해당 physical address는 <i, offset>이 되고 일치하는 것이 없으면 잘못된 메모리로 간주한다.
OS에 의한 ! - 안나옴
Segmentation with Paging - MULTICS
- The MULTICS system solved problems of external fragmentation and lengthy search times by paging the segments.
- Solution differs from pure segmentation in that the segment-table entry contains not the base address of the segment, but rather the base address of a page table for this segment.
MULTICS Address Translation Scheme
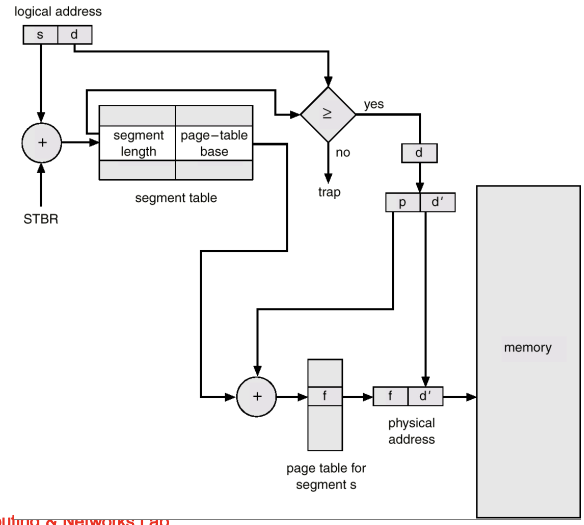
한 segment가 여러 개의 page로 나눠지니까 d -> p+ d`가 되었다.
Segmentation with Paging - Intel 386
- Intel 386 uses segmentation with paging for memory management with a two-level paging scheme.
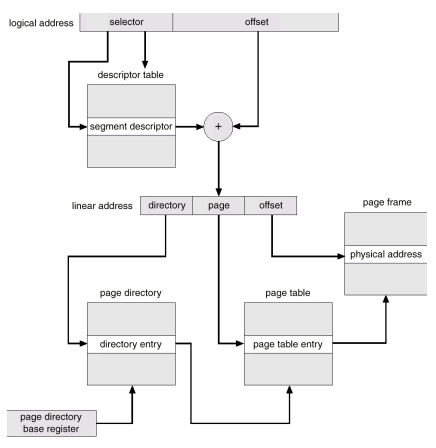
Example: The Intel 32 and 64-bit Architectures
- Dominant industry chips
- Pentium CPUs are 32-bit and called IA-32 architecture (x-86)
- Current Intel CPUs are 64-bit and called IA-64 architecture
- Many variations in the chips, cover the main ideas here
Example: The Intel IA-32 Architecture
- Supports both
segmentationandsegmentation with paging- Each segment can be 4 GB (4*109 Bytes)
- Up to 16 K segments per process
- Logical address space of a process is divided into two partitions
- First partition of up to 8 K segments are private to process (kept in local descriptor table (LDT))
- Second partition of up to 8K segments shared among all processes (kept in global descriptor table (GDT))
- Each entry in LDT & GDT consists of an 8-byte segment descriptor with detailed information about a particular segment including base location and limit of a segment
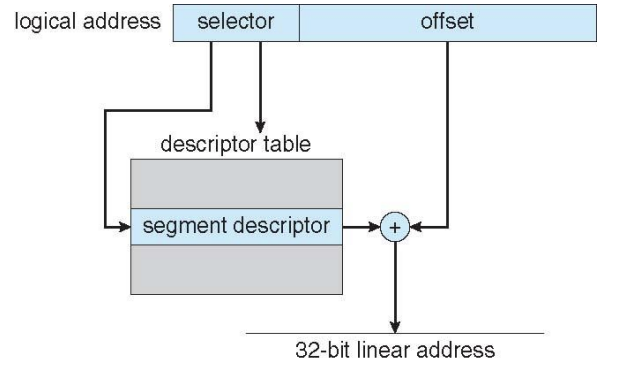
Example: The Intel IA-32 Architecture (Cont.)
-
CPU generates logical address
-
Logical address is a pair of (selector, offset)
-
Selector(16 bits) given to segmentation unit
-
Which produces linear addresses
-
s designates the segment number,
-
g indicates whether the segment is in GDT or LDT
-
p deals with protection
-
offset (32 bits) specifying the location of the byte within the segment

-
-
Linear address given to paging unit
- Which generates physical address in main memory
- Paging units form equivalent of MMU
- Pages sizes can be 4 KB or 4 MB
- For 4KB pages, two-level paging
-
Logical to Physical Address Translation in IA-32
Intel IA-32 Segmentation
Intel IA-32 Paging Architecture
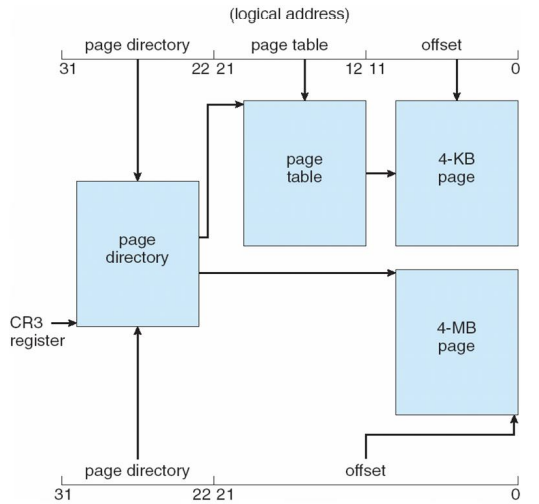
Intel IA-32 Page Address Extensions
- 32-bit address limits led Intel to create page address extension (PAE), allowing 32-bit apps access to more than 4GB of memory space
- Paging went to a 3-level scheme
- Top two bits refer to a page directory pointer table
- Page-directory and page-table entries moved from 32 bits to 64-bits in size
- Base address of page tables and page frames to extend from 20 to 24 bits
- Net effect of PAE is increasing address space (from 32 bits) to 36 bits – 64GB of physical memory (24 + 12 bit offset)
- 24: page에서 특정 frame을 찾아가기 위한 용도
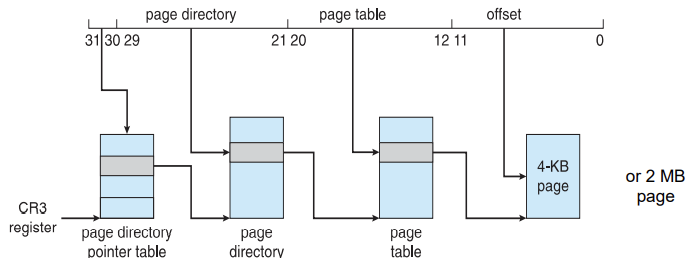
Intel x86-64
- Current generation Intel x86 architecture
- 64 bits is ginormous (> 16 exabytes 16*1018 : 264 bytes)
- In practice only implement 48 bit addressing for virtual addressing
- Page sizes of 4 KB, 2 MB, 1 GB
- Four levels of paging hierarchy
- Can also use PAE, so virtual addresses are 48 bits and physical addresses are 52 bits

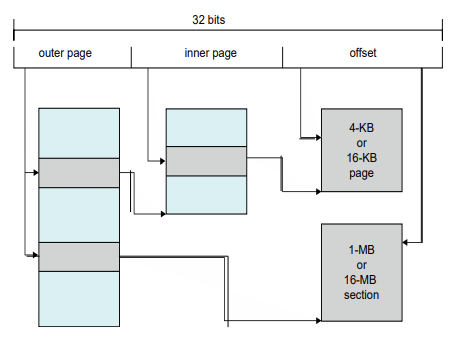
Example: ARM Architecture
- Dominant mobile platform chip (Apple iOS and Google Android devices for example)
- Modern, energy efficient, 32-bit CPU
- 4 KB and 16 KB pages
- 1 MB and 16 MB pages (termed sections)
- One-level paging for sections, twolevel for smaller pages
- Two levels of TLBs
- Outer level has two micro TLBs (one data, one instruction)
- Inner is single main TLB
- First inner is checked, on miss outers are checked, and on miss page table walk performed by CPU
ARMv8 4-level hierarchical paging
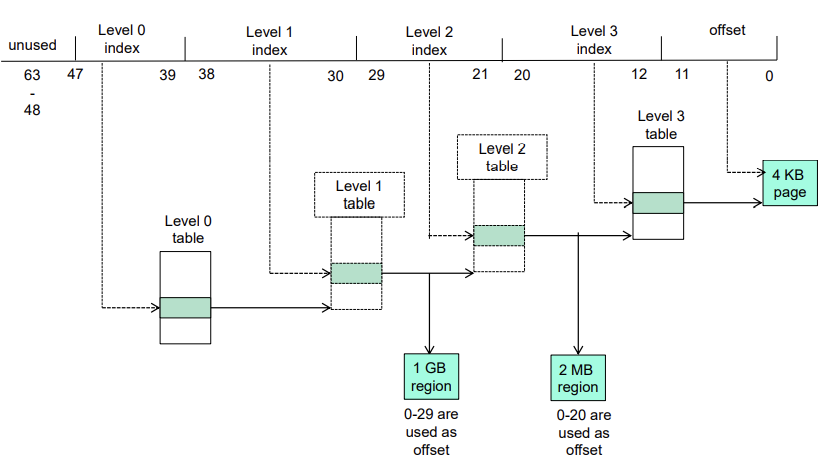
offset에 따라 paging level이 달라진다.
- 1GB region
- 2MB region
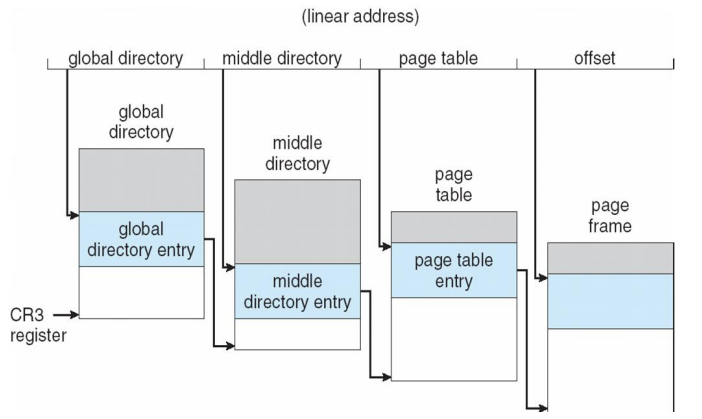
Linear Address in Linux
-
Linux uses only 6 segments (kernel code, kernel data, user code, user data, task-state segment (TSS), default LDT segment)
-
Linux only uses two of four possible modes – kernel and user
-
Uses a three-level paging strategy that works well for 32-bit and 64-bit systems
-
Linear address broken into four parts:

-
But the Pentium only supports 2-level paging?!
- linux의 3 level은 그러면 어떻게 사용해? -> 한 level 그냥 사용 안 해버리긔~
Three-level Paging in Linux
Comparing Memory-Management Startegies
- Hardware support
- Performance
- Fragmentation
- Relocation
- Swapping
- Sharing
- Protection
- -> Refer to summary section in text boo
댓글남기기