
[OS] Synchronization Tools
[toc]
Chapter 6: Synchronization Tools
- Background
- The Critical-Section Problem
- Peterson’s Solution
- Synchronization Hardware
- Mutex Locks
- Semaphores
- Classical Problems of Synchronization
- Monitors
Objectives
- To present the concept of process synchronization.
- To introduce the critical-section problem, whose solutions can be used to ensure the consistency of shared data
- To present both software and hardware solutions of the critical-section problem
- To examine several classical process-synchronization problems
- To explore several tools that are used to solve process synchronization problems
Background
그래도 결국 thread of control은 두 개가 아니라 하나.
- Processes can execute concurrently or in parallel
- CPU scheduler switches between processes to provide concurrent execution
- May be interrupted at any time, partially completing execution at any point in its instruction stream
- 언제든지 interrupt가 걸릴 수 있음
- time quatum expired(software interrupt)
- 외부에서의 이벤트 발생 -> interrupt -> control이 잠시 OS로 내려가서 판단
- Processing core may be assigned to execute instructions of another process (concurrent execution)
- 언제든지 interrupt가 걸릴 수 있음
- Two instruction streams (different processes) execute simultaneously on separating processing cores (parallel execution)
- 2개의 core에서 찐 parallel 하게 실행
- 외부에서 interrupt가 걸리지 않아도 두개 이상의 stream이 동시에 실행된다.
- Concurrent access to shared data may result in data inconsistency
- 1번을 다 끝내지 못한 상태에서 2번을 실행하게 되버리면 1번에서 사용하던 데이터를 2번에서 공유데이터로 쓰게 되어 버릴 수 있다.
- 믿을 만한 데이터인지 -> 데이터의 신뢰성이 떨어짐
- 은행 계좌 얘기 - 각자 계좌를 따로 쓰면 문제가 없겠지만 가족끼리 계좌를 같이 쓰면 이것이 사실상 공유 데이터 인 것이다. 만약 동시에 10만원을 뽑게 되면 자칫해서 은행은 10만원을 손해를 볼 수 있음
- 그래서 synchronization이 굉장히 중요한 것
- Maintaining data consistency requires mechanisms to ensure the orderly execution of cooperating processes
- 협력 관계의 프로세스 간에는 반드시 실행의 순서를 제어할 필요가 있다.
- 독립적이면 필요없음
- parallel processing이나 pseudo parallel processing이나 얻을 수 있는 장점이 있음.
Cooperating Processes
- Independent process cannot affect or be affected by the execution of another process.
- Cooperating process can affect or be affected by the execution of another process
- Directly share a logical address space (code and data)
- Share data through shared memory or message passing
- Advantages of process cooperation
- Information sharing
- Computation speed-up
- Modularity
- Convenience
Producer-Consumer Problem
- Illustration of the problem:
- Suppose that we wanted to provide a solution to the consumer-producer problem that fills all the buffers.
- We can do so by having an integer counter that keeps track of the number of full buffers.
- Initially, counter is set to 0. It is incremented by the producer after it produces a new buffer and is decremented by the consumer after it consumes a buffer.
- Paradigm for cooperating processes, producer process produces information that is consumed by a consumer process.
- unbounded-buffer places no practical limit on the size of the buffer.
- bounded-buffer assumes that there is a fixed buffer size.
Ch 3 Bounded-Buffer Shared-Memory Solution
-
Shared data
-
#define BUFFER_SIZE 10 typedef struct { . . . } item; item buffer[BUFFER_SIZE]; int in = 0; int out = 0;
-
-
10개의 item을 저장할 수 있는 buffer
-
if in=out, buffer is empty
-
if (in+1) mod n = out, buffer is full
-
Solution is correct, but can only use BUFFER_SIZE-1 elements
Bounded-Buffer - Producer
while (true) {
/* produce an item in next produced */
while (((in + 1) % BUFFER_SIZE) == out)
; /* do nothing */
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
}
Bounded Buffer - Consumer
item next_consumed;
while (true) {
while (in == out)
; /* do nothing */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
/* consume the item in next consumed */
}
Producer (counter)
while (true) {
/* produce an item in next produced */
while (counter == BUFFER_SIZE) ;
/* do nothing */
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
- 버퍼를 하나 비워야만 하던 문제를 해결하기 위해 counter 변수로 버퍼의 데이터 갯수를 센다.
Consumer (counter)
while (true) {
while (counter == 0)
; /* do nothing */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--; //이 부분을 atomic하게 실행하도록 만들어 주어야 함
/* consume the item in next consumed */
}
producer가 증가시키는 동안에는 consumer가 감소하지 않도록 해야 함.
Race Condition
위 코드는 잘못된 코드임 -> atomic 하지 않음!
-
조작하고 있는 사이에 Context Switching이 일어나게 되면 그 값은 원하는 결과를 가져오지 못할 것이다.
-
counter++ could be implemented in machine language as:
register1 = counter [r1=5]
register1 = register1 + 1 [r1=6]
counter = register1 [counter=6]
- counter를 증가시키는 문장이 atomic하지 않다(아래도 마찬가지)
-
counter– could be implemented in machine language as:
register2 = counter [r2=5]
register2 = register2 - 1 [r2=4]
counter = register2 [counter=4]
- 하나의 instruction이 실행되는 동안에는 어떤 interrupt가 와도 반응하지 않음(atomic instruction)
- 그러나 instruction 사이사이에는 interrutpt가 발생할 수 있어서 context switching이 일어난다.
Race Condition - 중요
-
If both the producer and consumer attempt to update the buffer concurrently, the assembly language statements may get interleaved.
-
한 번에 2개 이상의 Writer 프로세스가 접근하는 경우 => Writer는 한 번에 1개만 접근가능
-
critical section의 실행은 동시에 실행되지 않도록!
-
-
Interleaving depends upon how the producer and consumer processes are scheduled.
-
Assume counter is initially 5. One interleaving of statements is:
producer: register1 = counter (register1 = 5) producer: register1 = register1 + 1 (register1 = 6) consumer: register2 = counter (register2 = 5) consumer: register2 = register2 – 1 (register2 = 4) producer: counter = register1 (counter = 6) consumer: counter = register2 (counter = 4)
-
The value of count may be either 4 or 6, where the correct result should be 5.
-
More than one process accessing a shared variable –> race condition
- race condition에서 문제는 발생할 수도 있지만 문제가 발생할 수도 있는데 발생하면 큰일 난다.
- 낙하산이 펴질 때도 있고 안 펴질 때도 있다? -> ……
- Timing factors (interrupts) can cause incorrect results
- Intermediate results are used
- race condition에서 문제는 발생할 수도 있지만 문제가 발생할 수도 있는데 발생하면 큰일 난다.
-
The statements:
-
counter := counter + 1;
-
counter := counter - 1;
must be executed atomically. -> data consistency 보장
-
-
Atomic operation means an operation that completes in its entirety without interruption.
-
Race condition: The situation where several processes access – and manipulate shared data concurrently. The final value of the shared data depends upon which process finishes last.
-
To prevent race conditions, concurrent processes must be synchronized.
- race condition을 원천 봉쇄하는 것 -> 동기화의 목적!
-
공유 데이터에 대한 접근을 동기화!
Critical Section Problem
- Consider system of n processes {p0 , p1 , … pn-1 }
- n processes all competing to use some shared data
- Each process has critical section segment of code
- Process may be changing common variables(공유 데이터를 변경 가능!), updating table, writing file, etc
- When one process in critical section, no other may be in its critical section
- Critical section problem is to design protocol to solve this
- ensure that when one process is executing in its critical section, no other process is allowed to execute in its critical section.
- Each process must ask permission to enter critical section in entry section, may follow critical section with exit section, then remainder section
- Especially challenging with preemptive kernels
- preemptive kernel: kernel 안에서 preemption을 허용
- 이 경우 더 어려움
Critical Section
- Structure of process Pi

- 원래 코드는 critical section과 remainder section이 뭉쳐져서 한 부분을 이루어져 있었는데 race condition을 일으키는 부분이 있어서 이 부분을 따로 빼야 했음.
- –> entry section
- 딱 한 개만 돌도록 하기 위해서 순서를 결정하는 것임!
- entry section에 진입할 때 티켓을 뽑고 exit section에서 나갈 때 티켓 반납
Solution to Critical-Section Problem
critical section problem을 제대로 해결했는지 확인하기 위해서는 다음 세 조건을 만족시키는 지를 확인하면 된다.
-
Mutual Exclusion.
- critical section을 실행 중인 process는 반드시 오직 하나여야만 한다.
- 즉, 하나의 process가 critical section에 접근했으면 다른 프로세스는 접근하지 못해야 한다.
- If process Pi is executing in its critical section, then no other processes can be executing in their critical sections.
- mutual exclusion은 critical section 문제를 해결했는지를 따지는 중요한 근간이 되는 조건이지만 이를 만족하기 위해 노력하다 보면 아래와 같은 역효과가 생기기 마련이다.
- 그래서 아래 두 조건도 만족 시켜야 문제를 완전히 해결했다고 할 수 있음
- critical section을 실행 중인 process는 반드시 오직 하나여야만 한다.
-
Progress.
- 아무도 critical section에 들어갈 수 없는 상황이 만들어 지면 안된다. (그래서 아무도 critical section에 없는 상황)
- 한 critical section에서 실행되고 있는 프로세스가 없는 상황에서, 어떤 프로세스가 그 critical section에 들어가고 싶다고 선언했으면 들어갈 수 있어야 한다.!
- A process outside of its CS can not block another process from entering its own CS
- critical section에 막 들어가려고 하는 프로세스가 CS 밖에서 돌고 있는 process의 영향을 받아 CS 안으로 들어가지 못하는 경우
- If no process is executing in its critical section and there exist some processes that wish to enter their critical section, then the selection of the processes that will enter the critical section next cannot be postponed indefinitely.
- CS를 실행 중인 프로세스가 없는 상황에서 여러 프로세스가 동시에 CS에 들어가려고 하고 싶을 때 경쟁에 가담하는 프로세스들은 그들의 remainder section에서 실행중이지 않는 프로세스여야 한다.
- 누가 들어갈 지 선택해야 함.
- 그리고 결정과정은 무한정으로 지연돼서는 안된다.
-
Bounded Waiting.
- 입장권을 받기 위해 기다리고 있는데 FCFS로 하면 당연히 먼저온 사람이 먼저 들어가니까 기다려야 되는 시간은 내 앞이 몇 명이 서 있냐에 따라 결정되는데 번호표를 나눠주는 방법에 문제가 있으면 일찍 왔어도 늦게 들어갈 수 있게 된다.
-
A bound must exist on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted.
-
Assume that each process executes at a nonzero speed
-
No assumption concerning relative speed of the n processes.
- 프로세스가 Critical Section에 들어가기로 했으면 무한정 기다려서는 안된다. 일정 시간 안에 들어가야 한다.
Critical-Section Handling in OS
- Two approaches depending on if kernel is preemptive or non-preemptive
- Preemptive – allows preemption of process when running in kernel mode
- Non-preemptive – runs until exits kernel mode, blocks, or voluntarily yields CPU
- Essentially free of race conditions in kernel mode
Algorithm for Process Pi

Initial Attempt 1 to Solve Problem
- 가정: Only 2 processes, Pi and Pj
- turn - i => Pi can enter its critical section
- initially turn = i
- line 2: entry section
- line 4: exit section

- mutex가 보장됨
- initial 값이 i이기 때문에 처음에는 Pi만 들어갈 수 있기 때문
- critical section에 들어감. -> critical section을 빠져 나올 때
turn = j;라는 exit section을 거쳐서 Pj가 들어갈 수 있게 된다. - turn이라는 변수에는 i 이거나 j 둘 중 하나의 값만 가질 수 있음
- Satisfies mutual exclusion, but not progress (strict alternation)
- strict alternation: 반드시 i후에 j가 올 수 있음(내가 원할 때 critical section에 들어가지 못함)
- i - j - i - j -i - j - …….
- i가 critical section에서 빠져나오면서 turn을 j로 바꿔주는데 이 때 프로세스j는 while문에 갖혀있거나 remainder section을 실행 중일 것이다.
- 근데 j가 remainder section을 실행 중인 경우
- j가 remainder section에서 시간이 오래 걸려서 i가 먼저 remainder section을 모두 수행하고 다시 while 문에 들어가 critical section에 들어가고 싶어하는 상황이 생겨버리면 i는 앞서 이미 turn을 j에게 넘겨주었기 때문에 critical section에 아무 프로세스가 없음에도 불구하고 들어가지 못하는 상황이 생기고 만다.
- 근데 j가 remainder section을 실행 중인 경우
- deadlock - 서로가 양보해서 어느 것도 들어가지 못함
- bounded wait: 한 번만 기다리면 들어갈 수 있음
- strict alternation: 반드시 i후에 j가 올 수 있음(내가 원할 때 critical section에 들어가지 못함)
Initial Attempt 2 to Solve Problem
-
turn 말고 flag를 쓰자(진입 의사를 나타내는)
-
양보를 하기 때문에 mutex가 보장이 된다.
-
하지만 bounded waiting과 progress 요구 사항이 충족되지 않는다.
-
- initially flag [i] = flag [j] = false.
- flag [i] = true
- Pi ready to enter its critical section

- Satisfies mutual exclusion, but not progress requirement.
- 상대방의 진입 의사가 있으면 반드시 양보하기 때문에 mutual exclusion은 만족하지만,
- atomic한 instruction이 아니기 때문에 flag[i]와 flag[j]가 모두 true인 상황이 있을 수 있다.
- 그러면 서로 양보하기 때문에 progress 조건을 만족시키지 못함.
- If switch 2 statements in entry section, then no mutual exclusion
시험 나올 듯 3번!
-
MTX requirement is met
-
Progress Requirement is not met
T0: Pi sets flag[i] = true
T1: Pj sets flag[j] = true
both processes are looping forever
-
Bounded-waiting Requirement ?
- 내가 들어가고 싶은데 계속 못들어갈 수가 있느냐?( 두 프로세스 모두 동시에 들어가고 싶어하는 경우 )
- 그런 경우에 둘 다 양보하는데 이것이 bounded -waiting 조건을 만족 시키는 것인지 아닌지
Peterson’s Solution
위의 결함으로 나온 것이 peterson’s solution
- Good algorithmic description of solving the problem
- Two process solution
- Assume that the LOAD and STORE machine-language instructions are atomic; that is, cannot be interrupted
- The two processes share two variables:
- int turn;
- Boolean flag[2]
- initially flag [0] = flag [1] = false
- The variable ‘turn’ indicates whose turn it is to enter the critical section
- 누가 critical section에 들어갈 차례인지
- The flag array is used to indicate if a process is ready to enter the critical section. flag[i] = true implies that process Pi is ready to enter its critical section!
- 각 프로세스가 critical section에 들어갈 준비가 되었는지(while문 직전에 true가 됨)
- 프로세스를 2개인 경우를 가정한 것이므로 프로세스의 갯수가 N개로 늘어나면 코드를 수정해야 함.
Algorithm for Process Pi

- 상대방이 들어갈 수 없는 경우에 들어갈 수 있음
-
flag[j] == false turn == i 인 경우에 CS에 들어갈 수 있음 - 상대방이 의사진입을 희망하고 있고 turn도 상대방으로 되어 있으면 못 들어감
-
- 상대방이 들어갈 의사가 없는 경우 -> 무조건 들어감
- 나도 상대방도 들어갈 의사가 있으면 turn 값을 보고 결정!
- Combined shared variables of initial attempts 1 and 2.
- Meets all three requirements; solves the critical-section problem for two processes.
- Problem: does not generalize well
- n개의 process 상황으로 확장하기가 어려움
- Very difficult to expand to more than 2 processes
Peterson’s Solution (Cont.)
-
to enter the CS, process Pi first sets flag[i] to be true and then sets turn to value j , thereby asserting that if the other process wishes to enter CS it can do so.
- 들어가고 싶다는 의사 표시는 하지만 turn은 상대방에게 양보
-
Provable that the three CS requirement are met:
-
Mutual exclusion is preserved Pi enters CS only if: either
flag[j] = false or turn = i -
Progress requirement is satisfied
-
Bounded-waiting requirement is met
Pi will enter CS (progress) after at most one entry by Pj
-
Multiple-Process Solution: Bakery Algorithm
Critical section for n processes
- Before entering its critical section, process receives a number.
- Holder of the smallest number enters the critical section.
- 가장 작은 숫자를 가진 애가 들어감
- If processes Pi and Pj receive the same number, if i < j, then Pi is served first; else Pj is served next .
- 이 번호들은 unique한 번호가 아니기 때문에 문제가 생김!
- 만약 같은 number를 부여 받으면 pid가 더 작은 애가 들어갈 권리가 주어짐.
- The numbering scheme always generates numbers in increasing order of enumeration; i.e., 1,2,3,3,3,3,4,5…
- 왜 똑같은 번호를 받는 프로세스가 생길까…?
- 이 경우 pid가 작은 프로세스가 들어가는 것으로 해결
Bakery Algorithm (Cont.)(중요)
프로세스가 N개일 때도 만족하는 알고리즘
-
Notation <= lexicographical order (ticket #, process id #)
- (a,b) < (c,d) if a < c or if a = c and b < d
- max (a0 ,…, an-1 ) is a number, k, such that k >= ai for i - 0,…, n – 1
-
Shared data
var choosing: array [0..n – 1] of boolean; –> 번호표를 할당 받고 있는 상태 number: array [0..n – 1] of integer,
Data structures are initialized to false and 0 respectively

-
i, j는 pid
- 하지만 보면 알겠지만 entry section이 너무 복잡함
- 사용자가 하는 것은 사실상 불가능
- 두 번째 문장이 atomic하지 않아서(번호표 뽑는 문장 - number[i] = max ….) 동일한 번호가 발부 되는 것
- 그러나 같은 번호를 발급받지 못해야 한다.
- 같은 번호면 pid가 작은 애를 찾음(loop를 돌면서)
- 맨 위 세 문장을 실행시키고 있는 애들은
- choosing number가 false가 아니라면(즉 true라면) 발급 받는 중인 애인 것이다.
- number[i] = 0
- 발부 받은 번호표를 반납했거나 아직 번호표를 받지 못한 상태(임계 영역에 들어가지 않겠다는 의미)
1) MTX requirement is met consider Pi in its CS and Pk trying to enter CS. when Pk executes the second while statement for j==1, it finds that
- number[j] ≠ 0
- (number[j], j) < (number[i], i) 2) Progress Requirement is met
- critical section 밖에 있는 프로세스의 number[i]는 0이다. lexical order에 의해서 누군가 하나는 CS에 들어가게 된다.
- 그래서 CS에 아무도 없는데 못들어가는 경우는 있을 수 없음. 3) Bounded-waiting Requirement - ensures fairness - process enters CS on FCFS basis
- 늦게 온 프로세스가 먼저 될 수도 있긴하지만 번호표 + pid에 의해서 입장하기 때문에
peterson과 bakery는 FCFS가 보장되지 않음
- CPU busy waiting 때문에(먼저 왔다고 먼저 실행된다는 보장이 되지 않음)
Reordering of instructions - XXXX

- 컴파일러가 code optimization(코드의 실행속도를 빠르게 하기 위해 크게 문제가 없다고 판단하면 문장 순서를 바꾸는 것, 즉 reordering) 을 진행.
- 좋을라고 instruction reordering을 하지만 예기치 않은 상황이 일어날 수 있음(동기화 문제)
- dependency에 의해
- 그래서 memory_barrier();
- flag값이 x 값이 바뀌기 전에 바뀌면 안되게끔 - 즉 reordering이 되지 않게 해 준다.
- reordering이 되지 않기를 원하는 instruction 사이에 껴준다.
- 그래서 사용자는 이런 경우까지 고려해야 되므로 굉장히 골치 아픔.
- 만약 위 예제에서 thread 2의 순서를 바꾸지 않는다면 100이 출력 되겠지만 순서를 바꾼다면 flag를 true로 바꾸어 버려 기존 값인 0을 출력하고 그 후에 x값이 100으로 바뀐다.
- 이는 분명히 문제가 있는 경우이다. -> reordering을 하면 안됨
- reordering을 하려면 하기 전과 후의 결과가 반드시 같음을 보장해야 함!
- memory_barrier() : instruction reordering을 못하도록
Hardware Support for Synchronization: Memory barrier - XXXX
- Memory model
- Strongly ordered
- Where a memory modification on one processor is immediately visible to all other processors
- Weakley ordered
- Where a memory modification on one processor may not be immediately visible to all other processors
- Strongly ordered
- Memory model vary by processor type
- Kernel can not make any assumption regarding the visibility of modification of memory on a shared memory multiprocessor
- Memory barriers or memory fences instruction
- Ensure that memory modifications are visible to threads running on other processors
- When they are executed, it ensures that all loads and stores are completed before any subsequent loads or stores are performed
Effects of Instruction reordering - XXXX
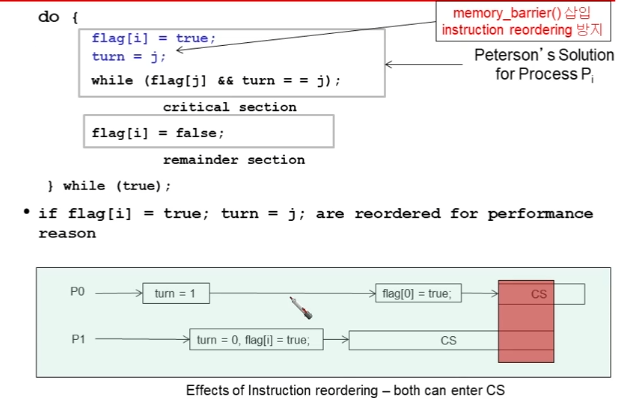
- instruction reordering을 하면 무슨일이 벌어지는 지
Synchronization Hardware
- Many systems provide hardware support for implementing the critical section code.
- All solutions below based on idea of locking
- Protecting critical regions via locks
- Uniprocessors – could disable interrupts
- Currently running code would execute without preemption
- Generally too inefficient on multiprocessor systems
- Operating systems using this not broadly scalable
- Modern machines provide special atomic hardware instructions
- Atomic = non-interruptable
- Either test memory word and set value
- Or swap contents of two memory words
Solution to Critical-section Problem Using Locks

test_and_set Instruction
-
Test and modify the content of a word atomically.

- 위는 atomic하지 않음. but hardware로 구현되어 있기 떄문에 interrupt가 걸리지 않는다.
- Executed atomically (Non-interruptible)
- Returns the original value of passed parameter (lock)
- Set the new value of passed parameter to “TRUE”.
-
If multiple processes attempting to execute instruction, first successful process will have value false returned to it
- return 값이 통과가능 통과 불가능을 결정
Solution using test_and_set() - 중요
-
Shared Boolean variable lock, initialized to FALSE
-
Solution:

- test_and_set을 쓰면 복잡하게 쓰던 entry section 코드와 다르게 한 줄이면 끝난다.
- test_and_set이 true이면 do nothing을 실행하므로 lock이 걸리게 된다.
- hardware가 직접 해 주겠다.
- mutual exclusion 보장, progress도 보장, but bouned waiting은 보장 X
- test_and_set을 쓰면 복잡하게 쓰던 entry section 코드와 다르게 한 줄이면 끝난다.
- It works fine
- Problem:
- fairness (starvation) – no bounded waiting (한 놈이 계속 잡을 가능성이 있음.)
- Waste CPU cycle
- CPU cycles to check test&set routine
- CPU에 의해 저 문장이 계속 실행됨(useless) - CPU 시간 낭비
- CPU busy waiting!! -> 기다리는데 CPU를 바쁘게 만드는 것, 쓸데 없이
**왜 test_and_set은 no bounded waiting 문제가 일어나는가?
- 사용자가 짠 프로그램이기 때문에 while 문장
- 내가 먼저 while문장에 들어갔다고 나 다음에 while문에 들어와서 lock이 걸린 애들이 줄을 서고 있을 때 어떤 애가 먼저 한다는 보장이 있는가? -> No
- 누가 먼저 도착했다고 기록되는 것이 없기 때문,
- 최악의 경우 계속 들어가지 못할 수 있음
- 아무리 오래 기다렸어도 계속 못들어갈 수도 있다.
피터슨, 베이커리 - 직접
하드웨어의 도움 - swap
OS의 도움 - semaphore
compare_and_swap Instruction - XXXX
구현 내용만 다르고 동작은 test_and_set과 거의 동일함.
Definition:

- Executed atomically
- Returns the original value of passed parameter “value”
- Set the variable “value” the value of the passed parameter “new_value” but only if “value” ==“expected”. That is, the swap takes place only under this condition.
Solution using compare_and_swap - XXXX
- Shared integer “lock” initialized to 0;
- Solution:

- Problem:
- fairness (starvation) – no bounded waiting
- Waste CPU cycle
Bounded-Waiting Mutual Exclusion with Test_and_Set
중요
test_and_set은 entry section이 flag를 false로 바꿔주는 것으로 끝났지만 아래 코드는 bounded waiting을 보장하기 위하다 보니 코드가 굉장히 복잡해짐

- Shared data (initialized to false):
- boolean lock;
- boolean waiting[n];
- Satisfies all the CS requirements
// ---- 1. 각각의 프로세스들이 해당 코드에 진입하게 되면 각 프로세스의 해당하는 waiting 배열의 값을 TRUE로 바꿈으로써
Critical Section에 들어갈 준비가 됐다는 것을 의미합니다. 예를 들어 P0, P2, P4, P5가 진입하여 준비가 되었다고 하고
그중에 P2가 가장 먼저 도착했다고 가정해봅시다.
// ---- 2. P2가 먼저 도착하여 while 문을 들어가게 되면 TestAndSet 함수를 통해 lock을 얻고 P2는 진입한다는 의미로 waiting 배열의 값을 FALSE로 바꿔 준 후 Critical Section에 진입하고 나머지 프로세스들은 lock이 TRUE로 인한 TestAndSet의 반환값이 TRUE이므로 계속해서 while 문에서 대기하게 됩니다.
// ---- 3. P2가 Critical Section을 수행하고 자기 보다 큰 번호의 프로세스들 중 가장 작은 프로세스를 선택하게 됩니다. i는 현재 2이고 배열의 크기는 7이기 때문에 j의 값은 3이 되게 됩니다. 하지만 P3은 준비가 되어 있지 않은 상태이기 때문에 다시 한번 while 문 안으로 들어가 다음 프로세스가 준비되어 있는지를 검사하게 됩니다. 그리하여 j는 4가 되어 P4가 선택되고 waiting[j]가 FALSE가 되기 때문에 P4는 2번의 while 문을 벗어나 Critical Section을 들어가게 됩니다. 이런 식으로 모든 waiting 배열의 값이 FALSE가 되어 전부 통과되었다면 마지막 프로세스의 차례에서는 i와 j가 같아지게 됩니다. 그렇게 되면 서로 돌려가지던 lock을 최종 반납하고 모두 Critical Section을 벗어나게 됩니다.
-
MTX
-
Pi can enter CS only if either waiting[i] == false or key == false
- Value of key can become false only if testAndSet is executed
- waiting[i] can become false only if another process leaves CS
- -> Only one waiting[i] can become false
-
-
Progress Requirement

- a process exiting CS either sets lock to false, or sets waiting[j] to false to allow a process that is waiting to enter CS to proceed
-
Bounded-waiting Requirement
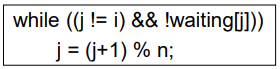
- any process waiting to enter CS will do so within n-1 times
Mutex Locks
user도 bounded waiting 보장이 안되고 HW도 not bad이지만 그냥 그렇기 때문에 OS의 도움을 한 번 받아볼까?
- Mutex_lock
- semaphore
- monitor
- Previous solutions are complicated and generally inaccessible to application programmers
- OS designers build software tools to solve critical section problem
- Simplest is mutex lock
- Product critical regions with it by first acquire() a lock then release() it
- Boolean variable indicating if lock is available or not
- Calls to acquire() and release() must be atomic
- Usually implemented via hardware atomic instructions
- But this solution requires busy waiting - 완전 중요
- This lock therefore called a spinlock
- Good locking mechanism used in multiprocessor system when lock is held for a short duration (duration of less than 2 context switches)
- mutex lock도 사실상 semaphore인데 CPU busy waiting 하는 semaphore를 spin lock이라고 한다.
- lock이 금방 풀리는 경우에는 original semaphore를 쓰게 되면 context swtich가 많이 일어나 overhead가 크다.
acquire() and release()
사용자 코드 기반에서 critical section을 들어갈 수 있는지 없는지를 판단하는 것은 OS가 할 수도, H/W가 할 수도 있음.

-
lock이 이미 걸려 있으면 즉, not available이면 기다린다.
-
내가 lock을 획득하면 다시 available을 false로 바꾸고 들어가는 거고, 획득하지 못하면 기다리고,마지막으로 나갈 때는 다시 lock을 반납
-
그렇다면 차이는?
-
test_set은 hardware로 구현
-
mutex lock은 OS 코드로 구현한 software
-
- available 하면 들어가고 available = false가 됨. -> CPU busy waiting
- 다른애가 못들어 가도록 false
- CPU time을 할애하면서 available이 true가 될 때까지 기다림
- critical section을 바로 들어가지 못하면 busy waiting(?)
- test_and_set보다 더 좋지 않지만 그럼에도 제공하는 이유?
- acquire 함수가 atomic하게 실행됨
Semaphore
얘는 CPU time을 낭비하지 않음 - CPU busy waiting을 필요로 하지 않는 locking mechanism
-
Synchronization tool that provides more sophisticated ways (than Mutex locks) for process to synchronize their activities.
-
Each process must perform operations on semaphore before entering its own CS
- Spinlock : no context switch required
- When locks are expected to be held for short times, spinlocks are useful
-
Semaphore S – integer variable
-
Can only be accessed via two indivisible (atomic) operations
- wait() (acquire) and signal()(release)
- Originally called P() and V()
- wait() (acquire) and signal()(release)
-
Definition of the wait() operation
wait(S) { while (S <= 0); // busy wait S--; } -
Definition of the signal() operation
signal(S) { S++; }
S가 lock
S값을 초기에 1로 해야 처음에는 들어가고 1이 감소하여 그 다음에 들어오는 애들은 busy waiting
그렇다면 CPU time을 낭비하지 않고 기다릴 수 있는 방법은 없나? -> 코드를 좀 수정해 보자(Implementation with no Busy waiting 코드)
Semaphore Usage
-
Counting semaphore – integer value can range over an unrestricted domain (값의 범위에 제한이 없음)
-
Binary semaphore – integer value can range only between 0 and 1 (오직 0 and 1)
- Same as a mutex lock
-
Can solve various synchronization problems
-
semaphore “mutex” initialized to 1

-
-
Consider P1 and P2 that require S1 to happen before S2
Create a semaphore “synch” initialized to 0

-
Can implement a counting semaphore S as a binary semaphore
Semaphore Implementation
- Must guarantee that no two processes can execute the wait() and signal() on the same semaphore at the same time
- 한 semaphore에 대해서 wait()이 끝나야지 만이 signal()이 호출될 수 있음
- Thus, the implementation becomes the critical section problem where the wait and signal code are placed in the critical section
- Could now have busy waiting in critical section implementation
- But implementation code is short
- Little busy waiting if critical section rarely occupied
- Could now have busy waiting in critical section implementation
- Note that applications may spend lots of time in critical sections and therefore this is not a good solution
Semaphore Implementation with no Busy waiting
- With each semaphore there is an associated waiting queue
- Each entry in a waiting queue has two data items: 구조체 변수에 다음을 포함
- value (of type integer)
- pointer to next record in the list (queue)
- Two operations:
- block – place the process invoking the operation on the appropriate waiting queue
- wakeup – remove one of processes in the waiting queue and place it in the ready queue
typedef struct{
int value;
struct process *list; /* list of process(waitlist) /*
} semaphore;
- linked list
- critical section 진입을 기다리는 프로세스들의 리스트 -> waitlist
Implementation with no Busy waiting (Cont.) 시험!
wait(semaphore *S) {
S->value--;
if (S->value < 0) {
add this process to S->list;
block();
}
}
signal(semaphore *S) {
S->value++;
if (S->value <= 0) {
remove a process P from S->list;
wakeup(P); /* place P onto ready queue */
}
}
- S나 lock은 int 변수였음.
- 근데 여기서는 history log를 저장하기 위해서 semaphore 구조체 타입이 된다.
- S값이 0보다 작다는 것은 나 말고 다른 애가 들어가 있다는 뜻
- while -> if 로 바뀜
- busy waiting을 막기 위함!
- 그 대신 linked-list의 대기 순번이 진입시킨다.
- 그러고 block 시킴 -> 왜?
- 코드가 실행중인 것이 OS인데 wait()을 호출 시킨 프로세스를 block(runnung-> waiting)시키는 것
- bounded waiting도 보장 - FCFS
- while -> if 로 바뀜
- S값은 1이 최대값임, 대기는 여러명이 할 수 있기 때문에 -1, -2, -3, … 이 가능함
- S가 0이라는 것은 signal을 호출한 프로세스가 유일하게 wait함수를 호출했던 프로세스였다는 뜻
- 하지만 잘못 사용하면 deadlock이 걸릴 수 있음
- entry section에서 잘못 사용하면 아무도 critical section을 진입하지 못하는 경우가 생길 수 있음
- 하지만 제일 강력한 방법
Semaphore as General Synchronization Tool(중요)
- Execute B in Pj only after A executed in Pi
- B라는 instruction을 반드시 A라는 instruction 이후에 실행하도록 제어하고 싶은 경우
- Use semaphore flag initialized to 0
- Code:
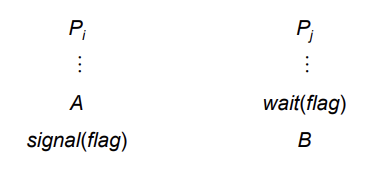
- A는 계에에속 해서 찍히지만 B는 그러지 못함
- wait(flag) - 1에서 0으로
- signal(flag) - 0에서 1로
- 그래서 A는 무한대 반복될 수 있음
- B는 A가 실행된 후 딱 한 번 실행 가능
- B가 연속으로 두 번 나올 수는 없음
Two Types of Semaphores
- Counting semaphore - integer value can range over an unrestricted domain.
- Binary semaphore – integer value can range only between 0 and 1; can be simpler to implement.
- Can implement a counting semaphore S as a binary semaphore.
Implementing S as a Binary Semaphore
-
Data structures:
var S1: binary-semaphore;
S2: binary-semaphore;
C: integer;
-
Initialization:
S1 = 1
S2 = 0
C = initial value of semaphore S
Implementing S (Cont.) - 중요
- wait operation
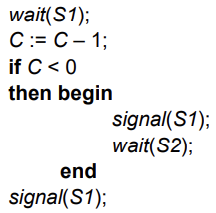
- signal operation

Problems with Semaphores
semaphore 사용할 때 주의점
- Incorrect use of semaphore operations:
- signal (mutex) …. wait (mutex)
- wait (mutex) … wait (mutex)
- Omitting of wait (mutex) or signal (mutex) (or both)
- Deadlock and starvation are possible.
Monitors
semaphore보다 사용하기는 아주 편하지만 semaphore보다 powerful 하지는 않음
-
A **Monitor** is an object designed to be accessed from multiple threads.
- A high-level abstraction that provides a convenient and effective mechanism for process synchronization
- Abstract data type(like class), internal variables only accessible by code within the procedure
- Ensure mutex at higher level, within monitor
- Only one process at a time can be executing within monitor
- Encapsulates data, procedures to manipulate data into one module
- Ensure mutex at higher level, within monitor
- Only one process may be active within the monitor at a time
- But not powerful enough to model some synchronization schemes

-
모니터에는 p1, p2,.. pn이 있을 것임.
- 한 프로세스가 실행되는 동안에 다른 프로세스가 호출되면
- 공유 데이터에 접근하게 되므로 monitor 안에 race condition이 생기기 때문에 하나로 제한시키는 것이다.
- 그래서 한 번에 하나의 프로세스만 모니터 안에서 실행이 가능
모니터 는 여러 스레드에서 액세스하도록 설계된 개체입니다. 모니터 개체의 멤버 함수 또는 메서드는 상호 배제를 시행하므로 지정된 시간에 하나의 스레드만 개체에 대한 작업을 수행할 수 있습니다. 한 스레드가 현재 개체의 멤버 함수를 실행 중이면 해당 개체의 멤버 함수를 호출하려는 다른 스레드는 첫 번째가 완료될 때까지 기다려야 합니다.
세마포어 는 하위 수준 개체입니다. 세마포어를 사용하여 모니터를 구현할 수 있습니다. 세마포어는 기본적으로 카운터일 뿐입니다. 카운터가 양수일 때 스레드가 세마포어를 얻으려고 시도하면 허용되고 카운터가 감소합니다. 스레드가 완료되면 세마포어를 해제하고 카운터를 증가시킵니다.
스레드가 세마포어를 얻으려고 할 때 카운터가 이미 0이면 다른 스레드가 세마포어를 해제할 때까지 기다려야 합니다. 스레드가 세마포어를 해제할 때 여러 스레드가 대기 중인 경우 그 중 하나가 세마포어를 가져옵니다. 세마포어를 해제하는 스레드는 이를 획득한 스레드와 동일할 필요는 없습니다.
모니터는 공중 화장실과 같습니다. 한 번에 한 사람만 입장할 수 있습니다. 그들은 다른 사람이 들어오지 못하도록 문을 잠그고, 할 일을 하고, 나갈 때 문을 엽니다.
세마포어는 자전거 대여소와 같습니다. 그들은 특정한 수의 자전거를 가지고 있습니다. 자전거를 빌리려고 하는데 무료 자전거가 있으면 가져갈 수 있고 그렇지 않으면 기다려야 합니다. 누군가 자전거를 반납하면 다른 사람이 가져갈 수 있습니다. 자전거가 있다면 다른 사람에게 돌려주도록 할 수 있습니다. --- 자전거 대여소는 자전거를 돌려받기만 하면 누가 돌려주든 상관하지 않습니다.
Monitors (continued)
- Initialization code is executed when monitor is declared
- 생성될 때 한 번만 실행
- Monitor procedures can only access variables declared within monitor, procedures
- Variables within monitor can not be accesses outside of monitor
- Only access to monitor is via calls to its procedures labeled entry
Schematic view of a monitor
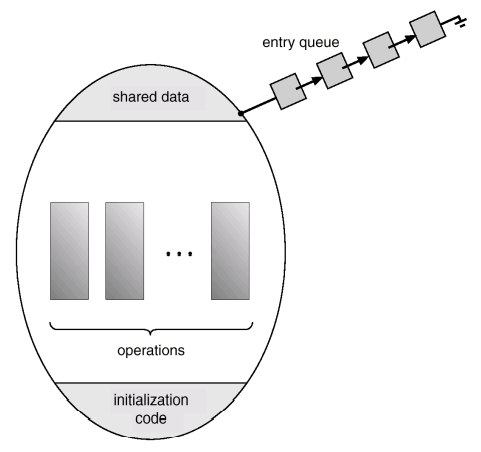
-
생성자 - initialization code
-
메소드 - procedure operation
- 모니터 안에서 생성될 수 있는 프로세스는 한 개로 제한
- entry queue: 모니터 안에서 정의된 procedure에 대해서 호출을 한 프로세스가 여러개 인 경우 그중 한 프로세스만 실행이 허용되고 나머지는 이 큐에서 순서대로 기다리는 개념
Monitors (continued) - 시험
procedure를 실행하다가 문제가 생긴 경우(event) - 모니터 안에서 기다리면 아무 것도 실행이 되지 않는 문제 발생(동기화에 대한 문제를 완전히 해결하지 못했음)
-> condition variable개념 도입
-
To allow a process to wait within the monitor, a condition variable must be declared, as
condition x, y;
- Associated with each condition is a queue
-
Two operations are allowed on a condition variable:
-
Processes placed onto / removed from queue via wait and signal (모니터에서 정의한)
- x means condition!
- x.wait() – means that the process that invokes this operation is suspended until another process invokes x.signal()
- event를 기다리는데 condition queue에 가서 기다리기
- x.signal() – resumes exactly one suspended process (if any) that invoked x.wait()
- If no x.wait() on the variable, then it has no effect on the variable
- semaphore는 no effect가 아니라 value가 0에서 1로 바뀐다!!!
- If no process is suspended, then the signal operation has no effect.
- x.wait에 의해 suspend된 프로세스를 살려줌
- If no x.wait() on the variable, then it has no effect on the variable
- semaphore의 wait과 signal과 혼돈하지 말 것
- condition 변수의 함수임
Monitor with condition variables
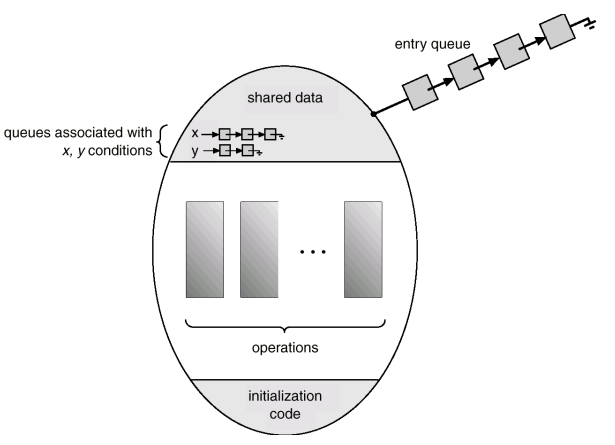
-
기본적인 모니터는 여러 동기화 기법 모델링을 위해서 충분히 강력하지가 않다.
- 공통된 자원에 대한 경쟁을 막기 위해서 mutex lock, semaphore를 사용하는데 이러한 semaphore와 mutex lock을 가지려는 대상들이 2개 이상일 때 condition variables을 통해서 그 대상들의 순서를 결정해 준다.
-
shared data의 queue는 무슨 역할?
- condition queue - 어떤 condition이 발생할 때까지 대기
-
실행을 하다가 event가 발생하여 더 이상 실행을 하지 못하는 경우 기다려야 하므로 손해
-
x라는 event가 발생하기를 기다리고 있는 프로세스
Monitors (continued)
- Suppose that, when the x.signal is invoked by a process P, there is a suspended process Q associated with condition x
- P -> x.signal 호출
- Q -> x.signal이 호출되어져 살아남
- 즉, P가 x.signal()을 주고 Q는 x.wait()에 걸려있는 상태이다.
- If the suspended process Q is allowed to resume its execution, the signaling process P must wait, otherwise, both P and Q will be active simultaneously within the monitor
- 이는 모니터 방식에 위배
- 2 possibilities
- Signal and wait – P either waits until Q leaves the monitor, or waits for another condition
- 살려준 프로세스가 기다릴 것이냐
- P는 Q가 monitor를 떠나거나 다른 조건을 기다릴 때까지 기다린다.
- Signal and continue - Q either waits until P leaves the monitor, or waits for another condition
- 살려진 프로세스가 기다릴 것이냐
- Q는 P가 monitor를 떠나거나 다른 조건을 기다릴 때까지 기다린다.
- Both have pros and cons – language implementer can decide
- Monitors implemented in Concurrent Pascal compromise
- P executing signal immediately leaves the monitor, Q is resumed
- Implemented in other languages including Mesa, C#, Java
- Signal and wait – P either waits until Q leaves the monitor, or waits for another condition
Monitor Implementation Using Semaphores
- Variables
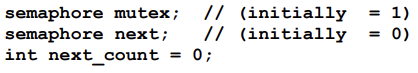
- Each procedure F will always be replaced by

- signal and wait
- wait(mutex) - entry section
- if-else : exit section
- body of F : critical section
- Mutual exclusion within a monitor is ensured by mutex semaphore
- Signaling process must wait until the resumed process either leaves or waits
- Next semaphore on which signaling processes may suspend themselves
- Next-count counts the number of processes suspended on next
- signal(next) - next
- 제일 우선순위 높은 ; next queue, entry queue, 새로들어온 애
- condition queue에 있는 애들은 우선순위 대상이 들어가지 않는 이유
- 남을 위해서 일부러 기다려주거나(next q) 다른 사람이 있기 때문에 기다리는 것(entry q)이 아니라 x 혹은 y라는 event를 기다리는 것이기 때문에 event에 의존하여 살려줘도 의미가 없는 경우가 있을 수 있다.
- 따라서 얘는 조건적으로 살아남
- condition queue에 있는 애들은 우선순위 대상이 들어가지 않는 이유
Monitor Implementation - Condition Variables
- For each condition variable x, we have:
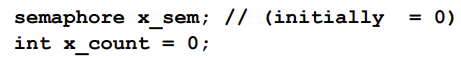
- The operation x.wait can be implemented as:

Monitor Implementation (Cont.)
- The operation x.signal can be implemented as:

Monitor Implementation (Cont.)
- Resuming Processes within a Monitor (monitor 내 프로세스들 재개하기!)
- If several processes queued on condition x, and x.signal() executed, which should be resumed?
- FCFS frequently not adequate
- Condition operation with priority (process resumption order)
- Conditional-wait construct: x.wait(c);
- c – integer expression evaluated when the wait operation is executed. (우선순위)
- value of c (priority number) stored with the name of the process that is suspended.
- when x.signal is executed, process with smallest associated priority number is resumed next.
Single Resource allocation
- Allocate a single resource among competing processes using priority numbers that specify the maximum time a process plans to use the resource

- Where R is an instance of type ResourceAllocator
- ex) ResourceAllocator R;
A Monitor to Allocate Single Resource - 중요

- release()에서 x.signal()을 하면 누가먼저 살아나야 할까? -> 위에서 말했음
- time의 시간이 작을 수록 우선순위가 높다면, time이 짧은 애가 먼저 wait을 빠져나간다.
Monitor Implementation (Cont.)
- Check to establish correctness of system:
- User processes must always make their calls on the monitor in a correct sequence.
- Must ensure that an uncooperative process does not ignore the mutual-exclusion gateway provided by the monitor, and try to access the shared resource directly, without using the access protocols.
이 아래는 뒤에서 배울 것이므로 무시
Liveness - 무시 XXXX
- Deadlock – two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes.
- Let S and Q be two semaphores initialized to 1
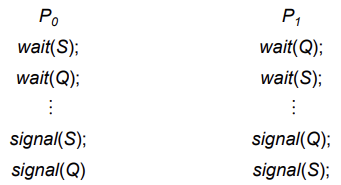
- Starvation – indefinite blocking.
- A process may never be removed from the semaphore queue in which it is suspended.
- Priority Inversion – Scheduling problem when lower-priority process holds a lock needed by higher-priority process
- Solved via priority-inheritance protocol
Atomic Transactions -XXXX
- System Model
- Log-based Recovery
- Checkpointing
- Concurrent Atomic Transactions
System Model - XXXX
- Assures that operations happen as a single logical unit of work, in its entirety, or not at all
- Related to field of database systems
- Challenge is assuring atomicity despite computer system failures
- Transaction - collection of instructions or operations that performs single logical function
- Here we are concerned with changes to stable storage – disk
- Transaction is series of read and write operations
- Terminated by commit (transaction successful) or abort (transaction failed) operation
- Aborted transaction must be rolled back to undo any changes it performed
Types of Storage Media - XXXX
-
Volatile storage – information stored here does not survive system crashes
- Example: main memory, cache
-
Nonvolatile storage – Information usually survives crashes
- Example: disk and tape
-
Stable storage – Information never lost
- Not actually possible, so approximated via replication or RAID to devices with independent failure modes
Goal is to assure transaction atomicity where failures cause loss of information on volatile storag
댓글남기기