
[OS] Virtual Memory
[toc]
Chapter 10: Virtual Memory
- Background
- Demand Paging
- Performance of Demand Paging
- Copy-on-Write
- Page Replacement
- Allocation of Frames
- Thrashing
- Memory-Mapped Files
- Allocating Kernel Memory
- Other Considerations
- Demand Segmentation
- Operating-System Examples
Objectives
- To describe the benefits of a virtual memory system
- To explain the concepts of demand paging, page-replacement algorithms, and allocation of page frames
- To discuss the principle of the working-set model
- To examine the relationship between shared memory and memorymapped files
-
To explore how kernel memory is managed
- 전체적인 흐름은 virtual memory를 관리하는 기법 중 하나인 demand paging에 대해서 공부를 하고 이 기법에 사용되는 알고리즘인 page replacement schemes에 관해 공부를 한다.
- 마지막으로 이러한 가상 메모리를 사용함으로써 발생할 문제점 중 하나인 Thrasing에 대해서 공부해 보도록 한다.
Background
- In Ch 9, MM strategies have same goal
- To keep many processes in memory simultaneously to allow MP
- Requires that an entire process to be in memory before process can execute
- Code needs to be in memory to execute, but entire program rarely used
- 사용되지 않는 것들도 탑재되는 문제
- Error code, unusual routines, large data structures
- Entire program code not needed at same time
- Consider ability to execute partially-loaded program
- Program no longer constrained by limits of physical memory
- Program and programs could be larger than physical memory
- Each program takes less memory while running -> more programs run at the same time
- Increased CPU utilization and throughput with no increase in response time or turnaround time
- Less I/O needed to load or swap programs into memory
- each user program runs faster
- Program no longer constrained by limits of physical memory
- Ch9에서 배웠던 Memory Management는 하나의 프로그램 전체를 실제 메모리에 올리는 방식을 사용했는데 virtual memory를 사용하면 당장 실행에 사용되는, 즉 필요한 부분만 딱 physical memory에 올려서 실행할 수 있다.
- 이것을 통해 생기는 장점은?
- 프로그램은 더 이상 physical memory의 실제 남은 공간이 얼마나 되는지에 대해서 program 시작 전에 고민할 필요가 없다.
- 프로그램이 전체가 다 올라가는 것이 아니기 때문에 더 많은 프로그램은 동시에 메모리에 올려 작업을 수행할 수 있다.
- 한 번에 올리는 소스의 양이 적기 때문에 HDD와 Main Memory간에 I/O 작업 속도가 빨라진다.
Background
- Virtual memory
- A technique that allows the execution of processes that are not completely in memory
- 모든 것을 다 탑재 시키지 않고도 프로세스를 실행시킬 수 있도록
- separation of user logical memory from physical memory.
- Only part of the program needs to be in memory for execution
- Need to allow pages to be swapped in and out. – Logical address space can therefore be much larger than physical address space (거의 무한대처럼 보임)
- each process has appearance of infinite memory (virtual address space) available to it
- Can deal with jobs with high memory requirement which system may not want to fulfill (in terms of multiprogramming)
- Overlay, dynamic loading (restriction)
- Need to allow pages to be swapped in and out. – Logical address space can therefore be much larger than physical address space (거의 무한대처럼 보임)
- Allows address spaces to be shared by several processes
- Allows for more efficient process creation
- More programs running concurrently
- Less I/O needed to load or swap processes
- A technique that allows the execution of processes that are not completely in memory
Background (Cont.)
- Virtual address space – logical view of how process is stored in memory
- Usually start at address 0, contiguous addresses until end of space
- Meanwhile, physical memory organized in non-contiguous page frames
- MMU must map logical to physical (translation)
- Virtual memory can be implemented via:
- Demand paging
- Demand segmentation
Virtual Memory That is Larger Than Physical Memory
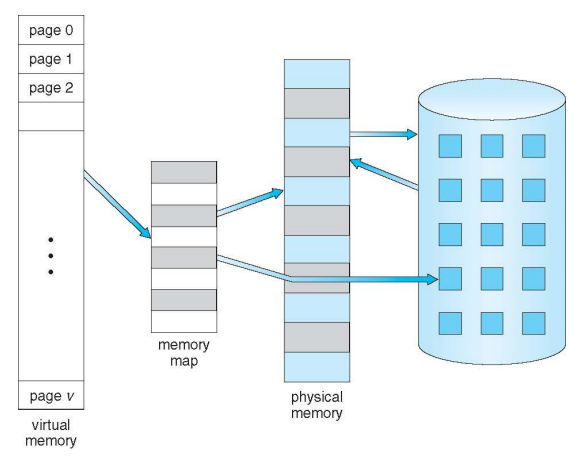
What should be done by OS
- To perform the idea, OS must maintain the following perspectives
- Which portion of a process will be in memory -> locality(집중적으로 사용되는 page 집합)
- In general, process is broken into pages
- When is a portion of job brought into memory
- On demand
- Maintain information regarding which portion of job are in memory
- Where they are located
- When they are taken out of memory
- Which portion of a process will be in memory -> locality(집중적으로 사용되는 page 집합)
Virtual-address Space
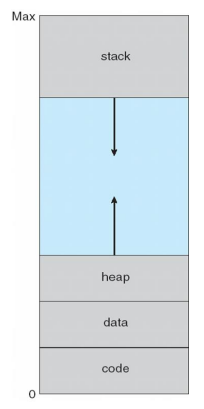
- Usually design logical address space for stack to start at Max logical address and grow “down” while heap grows “up”
- Maximizes address space use
- Unused address space between the two is hole
- No physical memory needed until heap or stack grows to a given new page
- Enables sparse address spaces(중간이 비어있으니까) with holes left for growth, dynamically linked libraries, etc
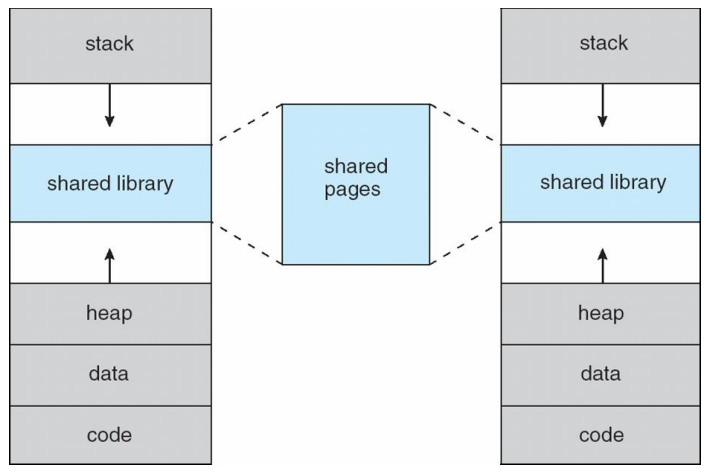
- System libraries shared via mapping into virtual address space
- Shared memory by mapping pages read-write into virtual address space
- Pages can be shared during fork(), speeding process creation
- code는 여러 프로세스와 공유하는 부분(read-only라서)
Shared Library Using Virtual Memory
Demand Paging
-
demand paging의 basic concept은 virtual memory가 추구하는 방식을 구현하는 기법으로 오로지 사용 중인 부분만 memory에 올리는 방법이다.
- Could bring entire process into memory at load time
- Or bring a page into memory only when it is needed
- Less I/O needed, no unnecessary I/O
- Less memory needed
- Faster response
- More users
- Similar to paging system with swapping (diagram on below)
- 앞에서 배웠던 swapping은 process 전체가 swap in, swap out 되는 것이었다면 paging system에서는 page단위로 swap in, swap out된다.
-
이를 구현하기 위해서 hardware의 support가 필요한데 그 이유는 valid-invalid Bit를 사용하기 때문이다.
- Page is needed => reference to it
- invalid reference => abort
- valid reference
- not-in-memory => bring to memory
- valid한 page지만 memory에는 탑재되지 않음!
- in-memory => OK (just referencing)
- not-in-memory => bring to memory
- Lazy swapper(on demand로 paging되기 때문) - never swaps a page into memory unless page will be needed
- 필요하지 않으면 절대 memory 안 가져올 거임 ㅡㅡ
- on-demand means -> reference 되어질 때
- Swapper that deals with pages is a pager
- 필요하지 않으면 절대 memory 안 가져올 거임 ㅡㅡ
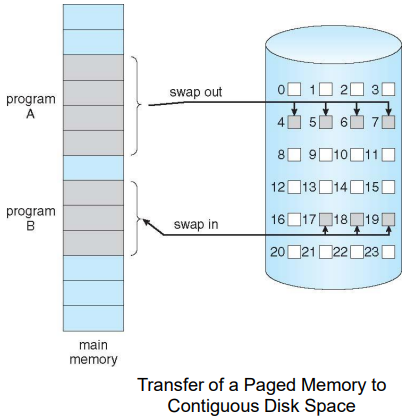
- When is a portion of process (page) brought into memory ?
- Demand paging (on-demand)
- Page is only brought into memory when needed
- lazy swapper:
- Swapper that deals with pages is a pager
- » view a process as a sequence of pages rather than one large contiguous address space
- Paging system with swapping ?
- Page is only brought into memory when needed
- Pre-fetching (Taking Guess)
- 추측하고 미리 fetch(하드웨어에서 읽어오는 시간을 줄임)
- Bring page into memory before it is needed
- Because I/O is slow, if guess is wrong then it costs high
- 만약 틀리면 그 대가가…크흠…
- Demand paging (on-demand)
Basic Concepts
- If pages needed are already memory resident
- No difference from non demand-paging
- If page needed and not memory resident
- Need to detect and load the page into memory from storage
- Without changing program behavior
- Without programmer needing to change code
- virtual memory는 application program logic 과 상관없이 OS에 의해서만 제공되는 기능
- Need to detect and load the page into memory from storage
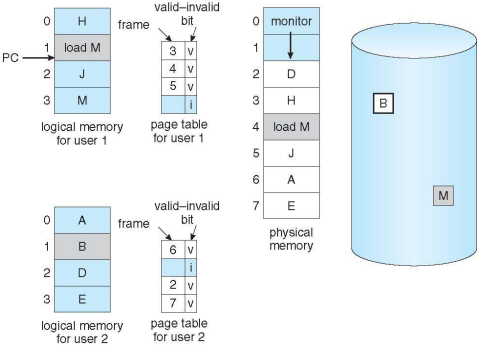
Valid-Invalid Bit
- With each page table entry a valid–invalid bit is associated (v => in-memory – memory resident, i => not-in-memory)
- Initially valid–invalid bit is set to i on all entries
- Example of a page table snapshot:
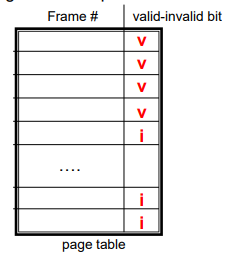
- During address translation, if valid–invalid bit in page table entry is I
- page fault
- 처리 -> i를 v로 바꿔주는 일 동작
- page fault
Page Table When Some Pages Are Not in Main Memory
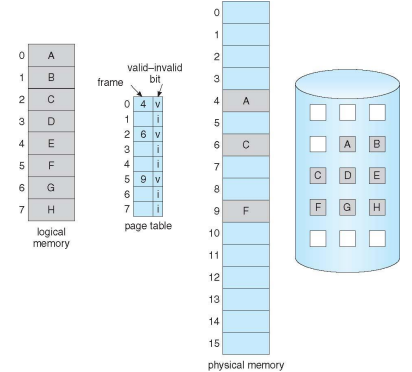
Page Fault
- Occurs when an attempt is made to access a location which is not in memory
- 지금 실행 시켜야 할 page가 physical memory에 올라와 있지 않는 것을 말한다.
- If there is a reference to a page, first reference will trap to OS
- CPU는 OS에게 이를 알리고(by trap) OS는 잠시 동안 CPU 작업을 멈춘다.
- page fault
- Cold faults
- Faults which occur in a process’s initial execution when its first page are brought into memory
- 절대 피할 방법 없음(얘 말고 일반적인 page fault를 줄이려고 노력해야 함.)
-
OS looks at another table to decide:
-
Invalid reference(뒤쪽에 붙어있는 테이블) => abort.
-
Just not in memory.
-
-
Get empty frame. (확보)
-
Swap page into frame via scheduled disk operation (disk I/O 요구)
-
Reset tables, to indicate page now in memory Set validation bit = v
-
Restart instruction that caused the page fault
- page fault를 일으켰던 명령어를 다시 실행하여 작업을 재개
Steps in Handling a Page Fault - 시험
위의 1~5 step을 그림으로 표현한 것(mapping 할 줄 알아야 함.)
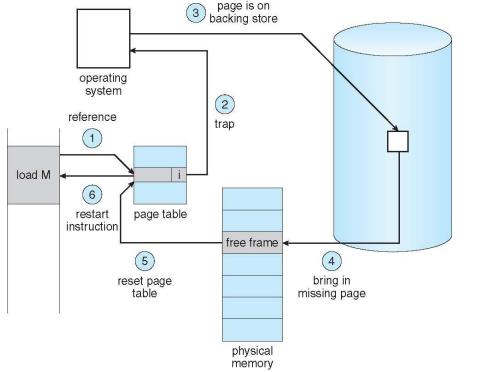
Aspects of Demand Paging
- Extreme case – start process with no pages in memory
- OS sets instruction pointer to first instruction of process, non-memory-resident -> page fault
- And for every other process pages on first access
- Pure demand paging (아무것도 탑재되지 않은)
- 성능 저해 요소가 있음
- Actually, a given instruction could access multiple pages -> multiple page faults
- Consider fetch and decode of instruction which adds 2 numbers (add와 같은 instruction을 생각해 보면 알겠지만 한 instruction 당 page가 3개는 있어야 함)
- 이는 3개의 page fault를 필수적으로 요구해야지 하나의 instruction이 실행됨.
- Pain decreased because of locality of reference
- Consider fetch and decode of instruction which adds 2 numbers (add와 같은 instruction을 생각해 보면 알겠지만 한 instruction 당 page가 3개는 있어야 함)
- Hardware support needed for demand paging (same as hardware for paging/swapping)
- Page table with valid / invalid bit
- Secondary memory (swap device with swap space)
- Instruction restart
Instruction Restart
-
Consider an instruction that could access several different locations (add 같은 instruction)
-
block move
-
Either block straddles a page boundary
-
-
auto increment/decrement location
-
Restart the whole operation?
- What if source and destination overlap?
-
Performance of Demand Paging (When page fault occurs)
normal page fault
cold faults
- Stages in Demand Paging (worse case)
- Trap to the operating system (interrupt)
- Save the user registers and process state (context switch) - handler가기 전에 이전 상태를 save
- Determine that the interrupt was a page fault (interrupt 종류가 머임?)
- Check that the page reference was legal and determine the location of the page on the disk (legal함?)
- Issue a read from the disk to a free frame: (읽어서 copy하라고 disk에게 요구)
- Wait in a queue for this device until the read request is serviced
- Wait for the device seek and/or latency time (HDD라서 필요한 부분)
- Begin the transfer of the page to a free frame
- While waiting, allocate the CPU to other process
- Receive an interrupt from the disk I/O subsystem (I/O completed)
- Save the registers and process state for the other process (context switch)
- Determine that the interrupt was from the disk
- Correct the page table and other tables to show page is now in memory (v -> i)
- Wait for the CPU to be allocated to this process again
- Job becomes ready, wait CPU to restart instruction
- Restore the user registers, process state, and new page table, (context switch) and then resume the interrupted instruction
Performance of Demand Paging (Cont.)
- Three major activities
- Service the interrupt - careful coding means just several hundred instructions needed
- Read the page - lots of time (HDD한테서 읽어야 돼서 오래 걸림)
- Restart the process – again just a small amount of time
- Page Fault Rate 0 ≤ p ≤ 1.0
- if p = 0 no page faults (demand paging을 하지 않는다)
- if p = 1, every reference is a fault (매 reference 마다 page fault가 일어남.)
- 이 때, reference는 특정 address에 대한 reference를 말하는 것이 아니라 page에 대한 reference임.
- Effective Access Time (EAT)

swap out이 왜 있지? -> swap in 을 하기 위해서 free frame을 찾아보았는데 free frame이 없으면 기존에 사용하던 page 중 일부를 swap out 해야해서 생기는 과정
Demand Paging Example
- Memory access time = 100 nanoseconds
- Average page fault service time = 25 milliseconds
- EAT = (1 – p) x 100 + p (25,000,000) = 100 + 24,999,900 X p
- effective access time is directly proportional to page fault rate
- If one access out of 1000 causes a page fault, the effective access time is 25 micro seconds
-
Computer would be slow down by a factor of 250 because of demand paging
- cold faults가 아닌 일반 page fault를 줄이는 방법 ? -> TLB cache! (cache의 hit ratio를 증가시킴으로써!)
- Memory access time = 200 nanoseconds (demand paging을 안한 경우)
- Average page-fault service time = 8 milliseconds
- EAT = (1 – p) x 200 + p (8 milliseconds) = (1 – p) x 200 + p x 8,000,000 = 200 + p x 7,999,800
- If one access out of 1,000 causes a page fault, then
- EAT = 8.2 microseconds.
- This is a slowdown by a factor of 40!! (demand paging을 안할 때보다 40배만큼 느려짐)
- If want performance degradation < 10 percent
- 220 > 200 + 7,999,800 x p 20 > 7,999,800 x p
- p < .0000025
- < one page fault in every 400,000 memory accesses
Demand Paging Example
-
Memory access time = 1 microsecond
-
50% of the time the page that is being replaced has been modified and therefore needs to be swapped out.
-
Swap Page Time = 10 msec = 10,000 msec
EAT = (1 – p) x 1 + p (15000)
1 + 15000P (in msec)
Demand Paging Optimizations - Handling of Swap Space
demand paging 성능을 올리는 방법
- I/O to Swap space is faster than file system I/O even if on the same device
- Swap space is allocated in larger chunks, less management needed than file system
- (file을 찾아가기 위해서는) File lookups and indirect allocation methods are not used
- Swap space is allocated in larger chunks, less management needed than file system
- For better paging performance,
- First option: Copy entire process image to swap space at process load time
- Then performing demand paging (page in and out) from the swap space
- Disadvantage: copying of the file image at program start-up(부담됨.)
- Second option: demand paging from the file system initially, but to write the pages to swap space as they are replaced
- file system에서 demand paging을 바로 하긴 하는데 memory 탑재되었던 page가 replace(swap-out) 될 때, swap space로 swap-out한다.
- 즉 최초의 page가 read 될 때만 file system으로부터!
- Ensure that only needed pages are read from the file system but that all subsequent paging is done from swap space
- Used in Linux, Windows
- file system에서 demand paging을 바로 하긴 하는데 memory 탑재되었던 page가 replace(swap-out) 될 때, swap space로 swap-out한다.
- First option: Copy entire process image to swap space at process load time
- Demand page in from program binary executable files on disk, but discard rather than paging out when freeing frame
- 수정되지 않은 부분의 swap-out은 그냥 버림.
- Because they are not modified, 상관없음
- can reduce the size of swap space
- Still need to write to swap space
- Swap space is used for the pages not associated with a file (like stack and heap) – anonymous memory
- Pages modified in memory but not yet written back to the file system
- Used in Linux, BSD Unix
- Mobile systems
- Typically don’t support swapping
- Instead, demand page from file system and reclaim read-only pages (such as code) from applications if memory becomes constrained
- Such data can be demand-paged from the file systems if it is later needed
- Under iOS, anonymous memory pages are never reclaimed from an application unless the application is terminated or explicitly releases the memory
- Compressed memory (alternative to swapping) is used in mobile systems
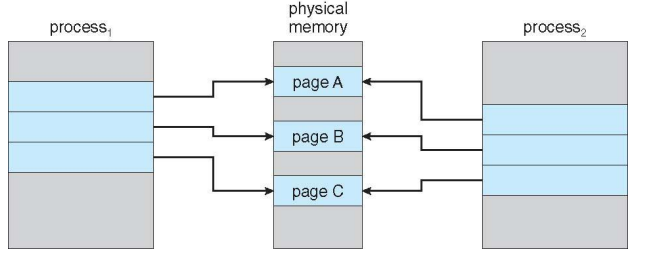
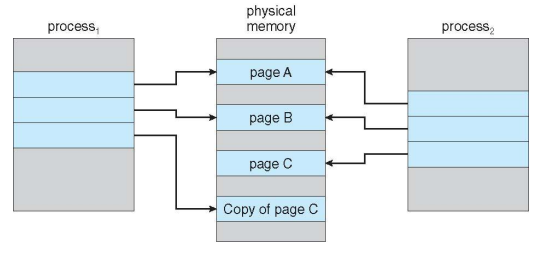
Copy-on-Write
- Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory (똑같은 프로세스 이미지를 copy하여 가지는 것이 아니라 똑같은 주소 공간을 공유함)
- child는 별도의 주소 공간이 만들어지지 않음
- If either process modifies a shared page, only then is the page copied
- write 하는 경우 copy를 만든다!
- COW allows more efficient process creation as only modified pages are copied
- 시간도 적게 걸리고 메모리 효율도 good!
- In general, free pages are allocated from a pool of zero-fill-on-demand pages
- Pool should always(항상, 미리) have free frames for fast demand page execution
- Don’t want to have to free a frame as well as other processing on page fault
- Why zero-out a page before allocating it?
- Pool should always(항상, 미리) have free frames for fast demand page execution
- vfork() variation on fork() system call has parent suspend and child using copy-on-write address space of parent
- Designed to have child call exec()
- Very efficient
Before Process 1 Modifies Page C
After Process 1 Modifies Page C
What Happens if There is no Free Frame? - 시험
- 왜 free frame이 없음? -> Used up by process pages (process page에 의해 모두 사용되었기 때문)
- Also in demand from the kernel, I/O buffers, etc
- How much to allocate to each?
- 프로세스 당 사용할 수 있는 free frame의 개수 제한
- 모든 page가 다 사용되는 것이 아니기 때문에
- 프로세스 당 사용할 수 있는 free frame의 개수 제한
-
“실제 메모리에 비어있는 Frame이 존재하지 않으면 어떡하지?”
- Page replacement – find some page in memory, but not really in use, page it out
- 즉, 현재 자신이 차지하고 있는 Frame을 지금 당장 실행해야 할 Page에게 넘겨 줄 Victim Frame을 찾는 과정
- 제한된 페이지 개수를 가진 프로세스가 페이지를 교체할 때 뭘(실제로 사용되지 않는) 빼고 넣을지 결정하는
- Algorithm – terminate? swap out? replace the page? - What page (of a job) in memory is going to be replaced by a new page which must be brought in ? (기준이 뭐임?)
- Performance – want an algorithm which will result in minimum number of page faults
- 잘 사용되지 않는 page를 교체하는 것으로 목표로 해야지 성능이 극대화됨.
- Same page may be brought into memory several times
- Reduce the # of page faults
Page Replacement
- Prevent over-allocation of memory by modifying page-fault service routine to include page replacement
- Use modify (dirty) bit to reduce overhead of page transfers – only modified pages are written to disk
- page in을 하고 읽기만 했으면 page out을 하지 않아도 되는데 page in을 하고 수정을 했다면 반드시 page out을 해주어야 한다.
- page out이 되어야 하는지 아닌지를 알려주는 bit가 modify bit(dirty bit)
- 즉, Modify Bit는 현재 메모리에 올라가 있는 Page들 중에서 내부 데이터가 바뀌었는지를 알려주는 Bit이며, 내부 데이터가 바뀌었다면 Disk와의 동기화를 위해 Swap-out 될 필요가 있다.
- 이러한 Swap-In/Swap-out은 많은 cost를 발생시키는데, 그래서 Victim Frame을 찾을 때는 Modify bit가 0, 즉 Swap-out 될 필요 없는 Frame을 우선적으로 찾아야 한다.(Swap-out 될 필요가 없으니 그 자리에 덮어 씌워버리면 그만이기 때문)
- Page replacement completes separation between logical memory and physical memory – large virtual memory can be provided on a smaller physical memory
Need For Page Replacement
Basic Page Replacement
- Find the location of the desired page on disk. (원하는 Page를 Disk에서 찾는다.)
-
Find a free frame: (비어있는 Frame을 찾는다.)
-
If there is a free frame, use it.
-
If there is no free frame, use a page replacement algorithm to select a victim frame.
- Write victim frame to disk if dirty (만약 dirty면 swap out을 먼저 해줘야 함.)
-
- Bring the desired page into the (newly) free frame. Update the page and frame tables.
- Disk에서 가져온 Page를 2번 과정에서 찾은 Frame 위치에 swap-in 하고 Frame Table과 Page Table을 update 시킨다.
- Continue the process by restarting the instruction that caused the trap
- instruction 재 실행
Note now potentially 2 page transfers for page fault – increasing EAT
Page Replacement
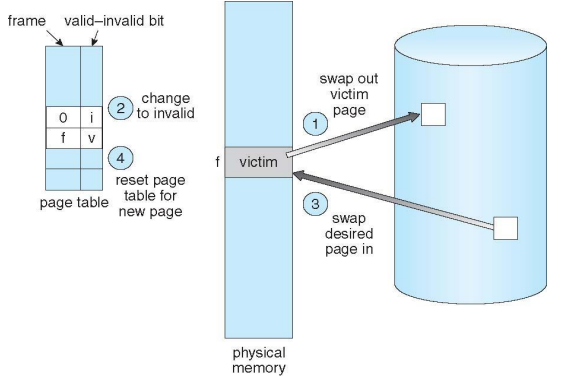
- 1번에 의해서 f 위치에 있는 victim frame을 swap out하기 때문에 page table에서 f에 대한 것을 v -> i로 바꿔준다.
- 3번에 의해서 page in 되기 때문에 다시 f 는 i->v로 바뀐다. (새로운 것으로 바뀌었음!)
Page and Frame Replacement Algorithms
- Frame-allocation algorithm determines
- How many frames to give each process
- Which frames to replace
- Page-replacement algorithm
- Want lowest page-fault rate on both first access and re-access
- Evaluate algorithm by running it on a particular string of memory references (reference string) and computing the number of page faults on that string
- String is just page numbers, not full addresses
- Repeated access to the same page does not cause a page fault
- Results depend on number of frames available
- In all our examples, the reference string is

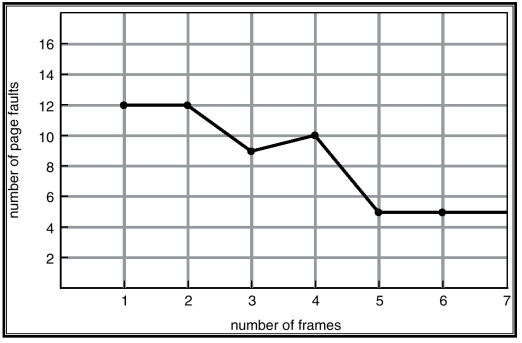
Graph of Page Faults Versus The Number of Frames
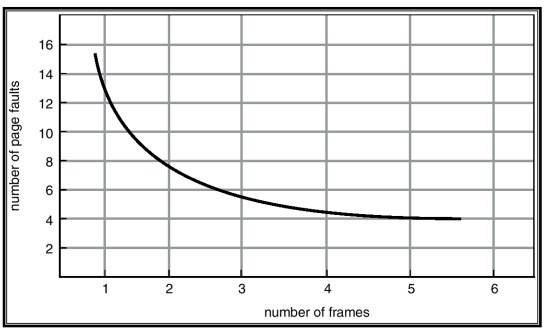
성능이 나빠지지 않는 선에서 frame수를 최소화
frame 수를 너무 늘려도 overhead
First-In-First-Out (FIFO) Algorithm
- 말 그대로 실제 메모리에 올라온 지 (Frame을 차지한 지) 가장 오래된 Frame을 선택한다.
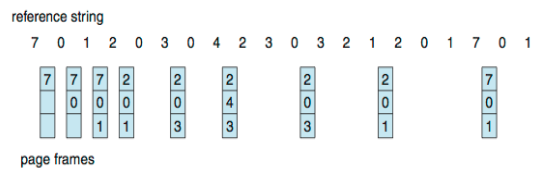
- Reference string: 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1
- Replace page which has been in memory for the largest period of time (탑재된 시점이 가장 오래된 것)
- 3 frames (3 pages can be in memory at a time per process)
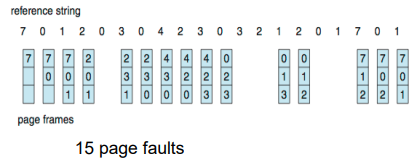
- 가장 오래된 걸 갈아치우면서 진행
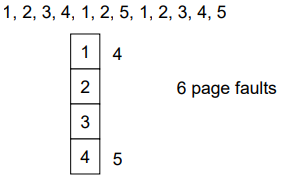
- Can vary by reference string: consider 1,2,3,4,1,2,5,1,2,3,4,5
- Adding more frames can cause more page faults!
- Belady’s Anomaly (규칙성이 없드라.)
- Adding more frames can cause more page faults!
- How to track ages of pages?
- Just use a FIFO queue
First-In-First-Out (FIFO) Algorithm
- Reference string: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
- 3 frames (3 pages can be in memory at a time per process)

- 4 frames
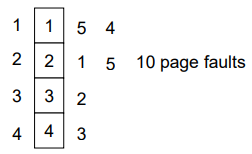
- FIFO Replacement – Belady’s Anomaly
- more frames => less page faults
- frame을 더 줬더니 page faults가 늘어났네? -> 모순이 존재
FIFO Illustrating Belady’s Anamoly
Belady’s Anomaly - 시험
- For certain replacement strategies, the page fault rate may increase for certain strings as the number of allocated frames increases
- Stack property

- At each point in any page reference string, the set of pages which would be in memory, if n pages were saved, is a subset of the pages which would be in memory if (n+1) pages were saved
- 페이지 참조 문자열의 각 지점에서, n개의 페이지가 저장되면 메모리에 있는 페이지 집합은 (n+1)개의 페이지가 저장되면 메모리에 있는 페이지의 하위 집합입니다.
- FIFO exhibits belady’s anomaly because it does not have stack property
- 왜 FIFO는 stack property를 갖지 않을까?
- Belady’s Anomaly 때문에 어쩌고 저쩌고
- belady’s anomaly 현상이 일어나는 이유는 stack property를 갖고 있지 않기 때문
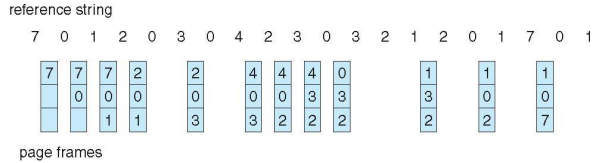
Optimal Algorithm
- Replace page that will not be used for longest period of time
- 가장 오랫동안 사용되지 않을 Frame을 Victim Frame으로 선택
- Replace page whose next reference is furthest in the future
- 9 is optimal for the example
- 가장 좋은 알고리즘이라서 optimal이라는 이름이 붙음
- How do you know this?
- Can’t read the future (구현이 불가능함… - 미래의 패턴을 보고 해야 하기 때문에)
- Used for measuring how well your algorithm performs(다른 알고리즘의 성능이 좋냐 안 좋냐 비교만 가능)
- Idea is to postpone next fault as long as possible
- 4 frames example
- 얘는 stack property를 갖고 있어서 page faults가 줄었어!
Least Recently Used (LRU) Algorithm
- Use past knowledge rather than future (과거의 패턴을 가지고 algorithm 결정)
- 가장 오랫동안 사용되지 않은 Page의 Frame을 선택!
- Select page for replacement which has not been used for the longest period of time
- Associate time of last use with each page
- 사용된 지 가장 오래된 page가 victim이 되어야 함(과거에도 사용 안 됐으면 나중에도 사용 안되겠지~)
- Idea: recent past reflects behavior of near future
- Page least likely to be used in near future is page used furthest in the past
- FIFO: time, LRU: Use
- 12 faults – better than FIFO but worse than OPT
- Generally good algorithm and frequently used
- But how to implement?
- 사용 시점을 표현하는 방식이 LRU에서 핵심 포인트
- 가장 최근에 실행되었으면 걔는 victim이 될 수 없음
More example
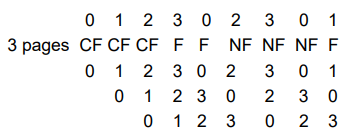
- NF - No fault
- CF - Cold Faults
- F - Fault
- 새로 들어오는 걸 top에 계속해서 두는 표현 방식 - 뒤에 있는 것들은 하나씩 아래로 밀어서 제일 아래 있던 것이 victim이 된다.
LRU Algorithm (Cont.)
- We can expect god performance, “if past is reflections of future behavior”
- Problem: difficult to implement efficiently: Stack, Counter
- Counter implementation
- Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter. (page가 reference가 될 때마다)
- When a page needs to be changed, look at the counters to find smallest value (to determine which are to change).
- Search through table needed (비교를 해야 하기 때문에 각각을 search 해야 함.)
- Stack implementation
- keep a stack of page numbers in a doubly linked list form:
- Page referenced:
- move it to the top
- 최대 : requires 6 pointers to be changed -> why?
- 현재 page가 stack에 존재한다면 해당 값을 stack의 top으로 옮겨 주어야 하기 때문에 최대 6개의 포인터를 바꾸어 주어야 하는 overhead가 생길 수 있다.
- But each update more expensive
- No search for replacement (스택의 top이 LRU 일것이고(가장 최근 사용) 맨 아래 깔린 게 victim이 될 것이기 때문 )
- LRU and OPT are cases of stack algorithms that don’t have Belady’ s
- stack property를 가짐!
Use Of A Stack to Record The Most Recent Page References
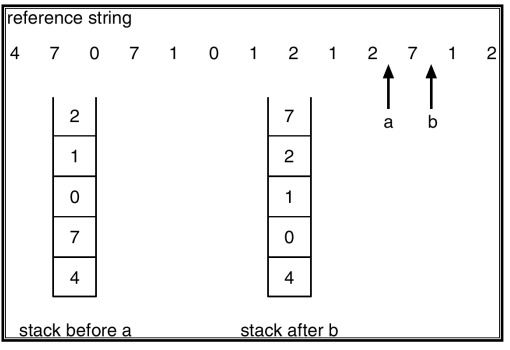
한 번 해 보기!
LRU Approximation Algorithms(유사 LRU)
-
LRU needs special hardware and still slow
- Inexact LRU
- Select page for replacement which has not been used recently
- Reference bit 사용 (by hardware 구현)
- With each page associate a bit, initially = 0
- When page is referenced bit set to 1
- Periodically clear bits.
- Replace the one which is 0 (if one exists).
- We do not know the order, however (누가 레퍼런스가 먼저 됐는 지 모름)
1. Additional reference bit 사용 (앞선 문제 해결)
- Shift register
- Maintain use bit for each page
- at periods, shift use bit into register
- Will shift in a 1 if used in that period, shift in 0 otherwise

가장 작은 값이 제일 오래있었던 page
- 오른쪽으로 shift 되기 때문에 가장 오래 된 것은 msb부터 쭉 0일 것이기 때문에
3. Second chance algorithm
- Generally FIFO, plus hardware-provided reference bit (FIFO + reference bit)
- Clock replacement.
- reference 되면 reference bit를 1로 바꿈
- If page to be replaced (in clock order) has
- Reference bit = 0 -> replace it
- Reference bit = 1. then:
- set reference bit 0, leave page in memory. (한 번 더 기회를 준다.)
- replace next page (in clock order), subject to same rules.(-> 다른 victim을 찾아 떠남)
- 모든 page의 reference bit가 1이라면 결국은 FIFO와 똑같이 작동
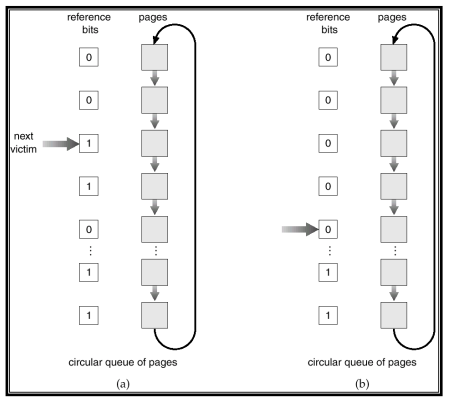
1번으로 setting 되어 있으면 바로 victim으로 선정하지 않고 두번 째 다시 체크하겠다.
3. Enhanced Second-Chance Algorithm
- Improve algorithm by using reference bit and modify bit (if available) in concert
- Take ordered pair (reference, modify)
- (0, 0) neither recently used not modified – best page to replace
- (0, 1) not recently used but modified – not quite as good, must write out before replacement
- (1, 0) recently used but clean – probably will be used again soon
- (1, 1) recently used and modified – probably will be used again soon and need to write out before replacement
- When page replacement called for, use the clock scheme but use the four classes replace page in lowest non-empty class
- Might need to search circular queue several times
Counting Algorithms
- Keep a counter of the number of references that have been made to each page.
- Not common
- Access 된 횟수를 Page table의 각 Page에다가 저장을 해서 그 값으로 Victim page를 선택한다.
- 1. LFU (Least Frequently Used)
- Algorithm: replaces page with smallest count.
- count 값, 즉 access 된 횟수가 가장 적은 페이지를 선택
- Suffers from the situation in which a page is used heavily during initial phase, but then is never used again
- 초반에만 많이 사용되고 나중에 잘 사용되지 않는 page와 초반엔 잘 사용되지 않다가 후반부에 많이 사용되는 페이지의 경우 LRU를 잘 찾아내지 못할 것이다.
- Solution is to shift the counts right by 1 bit at regular intervals, forming an exponentially decaying average usage
- Algorithm: replaces page with smallest count.
- 2. MFU (Most Frequently Used) Algorithm
- count 값, 즉 access 된 횟수가 가장 많은 페이지를 victim으로 선택
- based on the argument that the page with the smallest count was probably just brought in and has yet to be used.
- count값이 작은 페이지는 최근에 탑재된 페이지일 가능성이 높다.라고 해석
- 많이 access 되었다면 앞으로는 참조되지 않을 것이라고 판단
Page-Buffering Algorithms
demand paging의 성능을 높이기 위한 과정의 일종들
- Keep a pool of free frames, always (pool을 사용)
- Then frame available when needed, not found at fault time
- Read page into free frame and select victim to evict and add to free pool
- When convenient(편할 때 아무 때나), evict(쫓아내다) victim
- Possibly, keep list of modified pages (수정된 페이지 리스트로 관리)
- When backing store otherwise idle, write pages there and set to non-dirty
- Possibly, keep free frame contents intact and note what is in them
- victim으로 선정되었던 frame를 zero-out(초기화)을 하지 않게 되면 LRU 페이지 선정이 잘못 되어진 것을 조금 보정할 수 있게된다.
- If referenced again before reused, no need to load contents again from disk
- Generally useful to reduce penalty if wrong victim frame selected
Applications and Page Replacement
- All of these algorithms have OS guessing about future page access
- Some applications have better knowledge – i.e. databases
- 미래의 패턴을 알고 있음
- Memory intensive applications can cause double buffering
- OS keeps copy of page in memory as I/O buffer
- Application keeps page in memory for its own work
- Operating system can given direct access to the disk, getting out of the way of the applications
- Raw disk mode
- Bypasses buffering, locking, etc
Allocation of Frames
- Demand paging 에서는 프로세스가 당장 수행해야 할 부분에 대해서 최소한의 Frame 만을 할당하게 된다.
- 이러한 Frame을 할당해 주는 방법에도 몇 가지가 존재함.
- Each process needs minimum number of pages.
- Example: IBM 370 – 6 pages to handle SS MOVE instruction:
- instruction is 6 bytes, might span 2 pages.
- 2 pages to handle from.
- 2 pages to handle to.
- Maximum of course is total frames in the system
- Two major allocation schemes.
- fixed allocation
- priority allocation
- Many variations
Fixed Allocation
- Equal allocation
- 프로세스 목적과 성격에 상관없이 모든 프로세스에게 고정된 양의 Frame을 할당
- For example, if there are 100 frames (after allocating frames for the OS) and 5 processes, give each process 20 frames
- Keep some as free frame buffer pool
- Proportional allocation – Allocate according to the size of process.
- 프로세스 크기에 비례해서 Frame을 할당해 주는 방법
- Dynamic as degree of multiprogramming, process sizes change
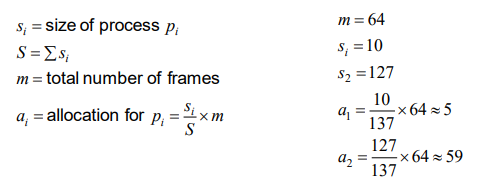
Priority Allocation
-
우선순위가 높은 프로세스에게 그만큼 더 많은 양의 Frame을 할당해 주는 방법.
- Use a proportional allocation scheme using priorities rather than size.
- If process Pi generates a page fault,
- select for replacement one of its frames.
- select for replacement a frame from a process with lower priority number.
- FIFO를 제외하고는 frame을 많이 주면 page fault가 줄어듦.
Global vs. Local Allocation
- Global replacement – process selects a replacement frame from the set of all frames; one process can take a frame from another
- 모든 프로세스의 모든 페이지에 victim을 찾음
- 다른 프로세스가 갖고 있는 frame도 victim으로 선정가능.
- But then process execution time can vary greatly
- But greater throughput so more common
- 모든 프로세스의 모든 페이지에 victim을 찾음
- Local replacement – each process selects from only its own set of allocated frames
- 해당 프로세스 내에서만 victim을 찾음
- More consistent per-process performance
- But possibly underutilized memory
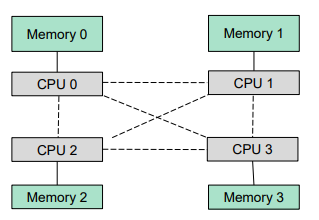
Non-Uniform Memory Access
- So far we assume that all memory accessed equally
- Many systems are NUMA – speed of access to memory varies
- Consider system boards containing CPUs and memory, interconnected over a system bus
- When a process incurs a page fault, a NUMA-aware virtual memory system will allocate that process a frame as close as possible to the CPU on which the process is running
- Optimal performance comes from allocating memory “close to” the CPU on which the thread is scheduled
- And modifying the scheduler to schedule the thread on the same system board when possible
- Solved by Solaris by creating lgroups (locality group)
- Structure to track CPU / Memory low latency groups
- Used my schedule and pager
- When possible schedule all threads of a process and allocate all memory for that process within the lgroup
NUMA Multiprocessing Architecture
Thrashing
- If a process does not have “enough” pages, the page-fault rate is very high.
- Page fault to get page
- Replace existing frame
- But quickly need replaced frame back
- This leads to:
- low CPU utilization.
- Spending more time paging than executing
- operating system thinks that it needs to increase the degree of multiprogramming.
- another process added to the system.
- low CPU utilization.
- Thrashing = a process is busy swapping pages in and out. (page in-out을 너무 많이 함.)
- Solution :
- provide a process as many frames as it needs
- 그것이 필요한 만큼 많은 프로세스를 제공한다.
- demanding page의 장점이 하나도 없어짐
- Then, How much ? => Working set model
- provide a process as many frames as it needs
- virtual memory 기법의 구현 원리는 그때 그때 필요한 부분만을 memory에 올려서 실행하는 것이고 당장 실행하지 않을 것 같은 부분은 디스크에 보관하는 것이다.
- 메모리에 올라간 부분들은 page table에 표시되어 각각 할당 받은 frame에 올라가게 된다.
- 하지만 만약 현재 실행 시점에서 필요한 부분이 메모리 상에 존재하지 않고 디스크에 존재하여 여유 frame이 없다면 디스크에서 필요한 부분을 찾아 swap-out 시킬 victim frame을 찾아 디스크로 보내거나 덮어씌운 후 새로 올린 부분의 명령어를 다시 실행시킨다.
- 이러한 현상을 Page Fault라고 하며 CPU 자원 효율성을 떨어뜨리는 현상 중 하나이다. 왜냐하면 resource를 할당 받은 시간 내에 CPU 자원을 사용하기보다는 I/O 작업에 시간을 더 소비하기 때문이다.
- Multi-programming은 CPU 자원의 효율성을 높이기 위해 보다 많은 프로세스에게 CPU를 할당해 주면서 자원을 더욱 바쁘게 효율적으로 관리하는 기법이다.
Thrashing (Cont.)
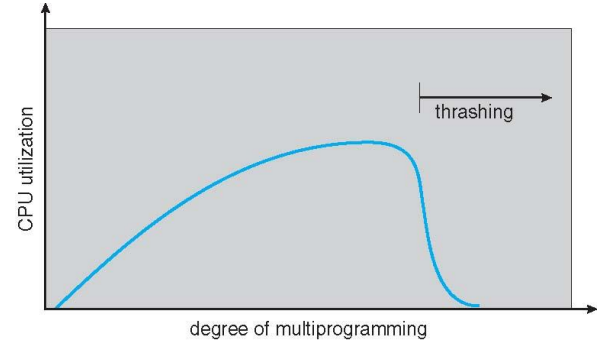
- 한정된 자원 안에서 OS는 efficiency를 높이기 위해 더 많은 process를 동시에 실행시키기 위해서 memory에 많은 프로세스를 올리게 된다.
- 이로써 CPU utilization은 높아지긴 하지만 동시에 실행 중인 process 의 개수 자체가 많아지기 때문에 각 프로세스가 할당받을 수 있는 자원의 양은 줄어들 수 밖에 없다.
- 그말인 즉슨, 할당 받을 수 있는 frame의 수도 줄어든다는 뜻인데, frame의 수가 줄어들면 앞서 말했던 것처럼 그 만큼 page fault가 많이 발생하게 되고, 그러면 자원의 활용보단 I/O 작업에 시간을 더 소비하게 된다.
- 이렇게 되면 프로그램의 진행속도는 굉장히 느려지고 CPU utilization 또한 굉장히 떨어지게 된다.
- 그런데 문제는 OS는 이러한 CPU 효율성이 떨어지는 것을 막기 위해 memory에 프로세스를 더욱 올리게 된다.(헉?)
- 이런 악순환으로 인해 CPU 효율성은 기하 급수적으로 떨어지게 되고(위 그래프와 같이) 결국 프로그램의 비정상적인 종료로 이어지는데
- 바로 이런 현상을 Thrasing이라고 한다.
Thrashing Diagram
- Why does demand paging work?
- Locality model: Program references cluster(집합) in localities
- goto를 사용하면 locality를 위배하기 쉬움
- Locality is set of pages actively being used together
- Once start referring to page within a locality, will continue to refer them for some time
- Process migrates from one locality to another.
- Once locality is exited (stop referring pages in locality), those pages will be referred to in frequently (in near future)
- Localities may overlap.
- Locality model: Program references cluster(집합) in localities
- Why does thrashing occur?
- ∑ size of locality > total memory size
- Limit effects by using local or priority page replacement
- ∑ size of locality > total memory size
Locality In A Memory-Reference Pattern
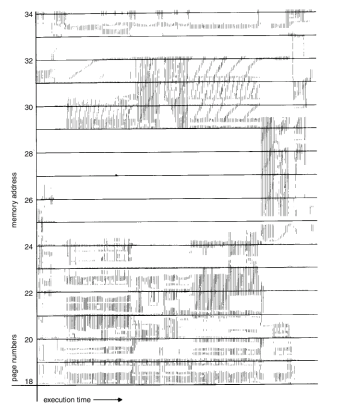
- 이러한 Locality map을 보면 알 수 있듯이 현 시점에서부터 일정 시점 전의 locality를 바탕으로 현재의 locality 영역을 추정하게 된다.
- 그래서 locality가 분기되는 시점(즉, locality의 영역이 급변하는 구간)에서는 순간적으로 page fault의 횟수가 치솟게 되지만 시간이 지날 수록 수치는 안정화 된다.
- 이렇듯 현재 시점으로부터 과거의 locality를 측정하게 될 때 이 시점의 간격을 Working set Size라고 한다.
Working-Set Model
적정선의 frame 개수가 얼마를 말하는 것이냐?
- Based on locality
- Strategy :
- prevents thrashing while keeping the degree of multiprogramming as high as possible
- Increase/decrease # of frames allocated to a job based on locality
- △ = working-set window = a fixed number of page references
- Approximate of program’s locality
- Example: 10,000 instruction
- WSSi (working set of Process Pi ) = total number of pages referenced in the most recent △ (varies in time)
- if △ too small will not encompass entire locality, lead too many page faults.
- if △ too large will encompass several localities.
- if △ = ∞ => will encompass entire program.
- D = ∑ WSSi = total demand frames
- approximation of locality
- if D > m => Thrashing
- Policy if D > m, then suspend one of the processes.
Working-set model
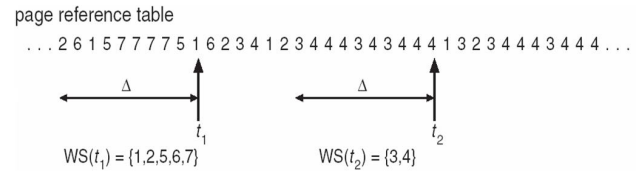
- 10개의 page가 reference 되는 것을 working set window로 잡았다.
- 10개의 page가 reference 되는 동안 5개의 page가 reference 되었다.
Keeping Track of the Working Set
- Approximate with interval timer + a reference bit
- Example: △ = 10,000
- Timer interrupts after every 5000 time units.
- Keep in memory 2 bits for each page.
- Whenever a timer interrupts copy and sets the values of all reference bits to 0.
- If one of the bits in memory = 1 => page in working set.
- Why is this not completely accurate?
- Improvement = 10 bits and interrupt every 1000 time units.
- of frames allocated to a job can vary, based on the # of pages in its working set
Page-Fault Frequency Scheme
- More direct approach than WSS
- How to prevent thrashing -> control the page fault rate
- Establish “acceptable” page-fault rate & control it.
- If actual rate too low, process loses frame.
- If actual rate too high, process gains frame.
- Check for reallocation only when a job experiences a fault
- upper bound와 lower bound 사이에 잘 있도록
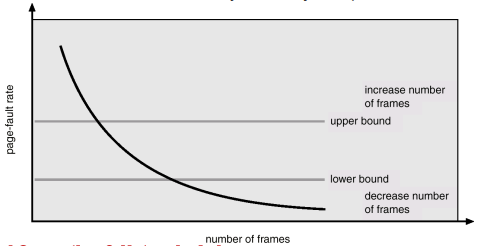
Working Sets and Page Fault Rates
- Direct relationship between working set of a process and its page-fault rate
- Working set changes over time
- Peaks and valleys over time

- We use a “use bit” & “clock”
- Define some parameter t, length of time
- When a page fault occurs
- if time_since_last_fault <= t then place new page in working set
- else mark for reallocation all pages not referenced since last fault
Process Creation
- Virtual memory allows other benefits during process creation:
- Copy-on-Write
- Memory-Mapped Files
Memory-Mapped Files
- File I/O using open(), read(), write() requires system call & disk access
- Open(), read(), write() 시스템 호출을 사용하여 디스크에 있는 파일을 사용하면 파일이 매번 접근될 때마다 시스템 호출을 해야 하고 디스크를 접근해야 한다. 이와같은 방법 대신 입/출력을 메모리 참조 방식으로 대신할 수도 있다.
- Memory-mapped file I/O allows file I/O to be treated as routine memory access by mapping a disk block to a page in memory
- 메모리 매핑(memory mapping)이라고 불리는 접근 방식은 프로세스의 가상 주소 공간 중 일부를 관련된 파일에 할애하는 것을 말한다.
- A file is initially read using demand paging
- A page-sized portion of the file is read from the file system into a physical page
- Subsequent reads/writes to/from the file are treated as ordinary memory accesses
- Simplifies and speeds file access by driving file I/O through memory rather than read() and write() system calls
- Also allows several processes to map the same file allowing the pages in memory to be shared
- But when does written data make it to disk? –
- Periodically and / or at file close() time
- For example, when the pager scans for dirty pages
Memory-Mapped File Technique for all I/O
- Some OS choose to memory-map a file regardless of whether the file was specified as memory-mapped
- Some OS provide memory mapping only through a specific system call and uses the standard system calls to perform file I/O
- memory mapped files for standard I/O
- In Solaris, process can explicitly request memory mapping a file via mmap() system call
- Now file mapped into process address space
- For standard I/O (open(), read(), write(), close()), mapping file into kernel address space
- Process still does read() and write()
- Copies data to and from kernel space and user space
- Uses efficient memory management subsystem
- Avoids needing separate subsystem
- COW can be used for read/write non-shared pages
Memory Mapped Files
Memory mapped files can be used for shared memory (although again via separate system calls)
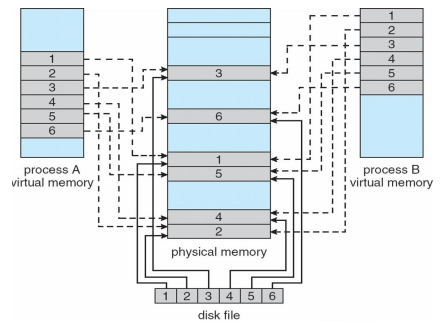
Memory-Mapped Shared Memory in Windows
생략
Shared Memory in Windows API - 생략
- First create a file mapping for file to be mapped
- Then establish a view of the mapped file in process’s virtual address space
- Consider producer / consumer
- Producer create shared-memory object using memory mapping features
- Open file via CreateFile(), returning a HANDLE
- Create mapping via CreateFileMapping() creating a named shared-memory object
- Create view via MapViewOfFile()
- Sample code in Textbook
Memory Compression
- An alternative to paging
- Rather than paging out modified frames to swap space, compress several frames into a single frame, enabling the system to reduce memory usage without resorting(의지) to swapping pages
Allocating Kernel Memory
- Treated differently from user memory
- Often allocated from a free-memory pool
- Kernel requests memory for structures of varying sizes
- Some kernel memory needs to be contiguous
- I.e. for device I/O
- 결국 kernel도 메모리에 존재하고 코드가 수행되어야 하는데 커널도 메모리 할당을 받아야 하기 때문에 해당 방식에 대해서 소개해 보도록 하겠다.
- 그 전에 대부분 kernel에서의 코드들은 paging 기법을 사용하지 않는다. 왜냐하면 page-in, page-out과 같은 동작을 하면 속도가 느려지기 때문에 이것이 시스템 전체에 영향을 미칠 여지가 충분하기 때문이다.
- 그래서 나온 메모리 할당 방식에는 Buddy System과 Slab Allocator가 있다.
Buddy System - 동작원리 중요
- Allocates memory from fixed-size segment consisting of physically-contiguous pages
- 고정된 크기의 segment를 할당해 준다.
- 고정된 크기라는 것은 2의 지수성 크기를 가져야 함을 말한다.(최소 4K)
- Memory allocated using power-of-2 allocator
- Satisfies requests in units sized as power of 2
- Request rounded up to next highest power of 2
- When smaller allocation needed than is available, current chunk split into two buddies of next-lower power of 2
- Continue until appropriate sized chunk available
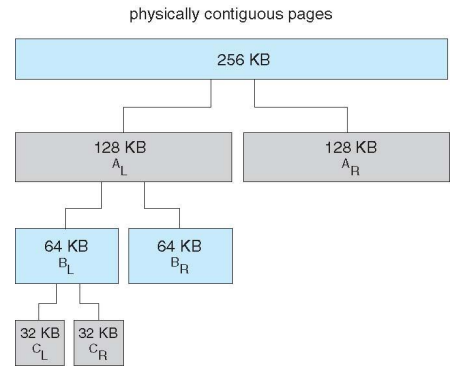
- For example, assume 256KB chunk available, kernel requests 21KB
- Split into AL and Ar of 128KB each
- One further divided into BL and BR of 64KB
- One further into CL and CR of 32KB each – one used to satisfy request
- One further divided into BL and BR of 64KB
- 만약 21KB를 요청하는데 256KB가 사용가능하다면 그것을 2개로 계속 나누어서 적당한 크기를 할당해 준다.
- 그런데 한쪽만 나눠지는 게 아니라 모두 짝을 맞춰서 나눠진다.
- Split into AL and Ar of 128KB each
- Advantage – quickly coalesce unused chunks into larger chunk (크기가 큰 요청이 오면 재빨리 합쳐서 주면 된다.)
- Disadvantage - fragmentation
Buddy System AllocatorS
Slab Allocator - 동작원리 중요
- Alternate strategy
- Slab is one or more physically contiguous pages
- 물리적으로 연속된 하나 이상의 페이지로 구성된 영역
- Cache consists of one or more slabs
- slab에서 사용하는 하나의 임시 보관소 개념 (우리가 아는 cache X)
- Single cache for each unique kernel data structure
- Each cache filled with objects – instantiations of the data structure
- When cache created, filled with objects marked as free
- When structures stored, objects marked as used
- If slab is full of used objects, next object allocated from empty slab
- If no empty slabs, new slab allocated
- Benefits include no fragmentation, fast memory request satisfaction
- 메모리의 기본 단위가 kernel object인데 그 size 만큼 cache를 구성하기 때문에 fragmentation이 존재하지 않음.
- 정리하자면 이 방식은 미리 다양한 size의 cache를 만들어 놓는 것이다. 즉, 하나의 kernel data structure에 대한 빈 object를 만들어 놓는 것.
- kernel에서 자주 사용되는 structure를 미리 만들어 놓으면 요청이 있을 때 바로바로 할당해 주면 된다. 그리고 사용이 완료되면 회수하는 형식으로 하면 굉장히 빠르게 처리할 수 있다.
Slab Allocation
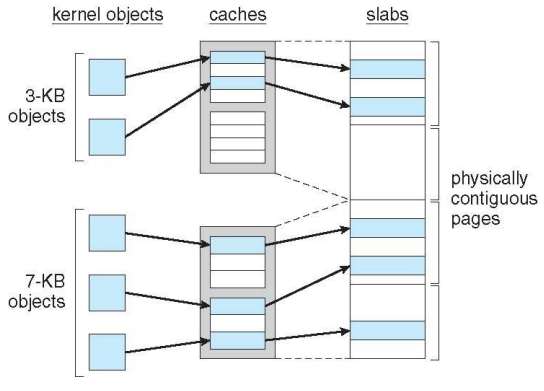
이렇게 되면 다양한 size를 만들어 놓을 수 있기 때문에 fragmentation을 줄일 수 있고, 메모리 요청에 대해서 빨리 처리할 수 있다.
Slab Allocator in Linux
-
For example process descriptor is of type
struct task_struct- PCB -
Approx 1.7KB of memory
-
New task -> allocate new struct from cache
-
Will use existing free
struct task_struct -
Slab can be in three possible states
-
Full – all used
-
Empty – all free
-
Partial – mix of free and used
-
-
Upon request, slab allocator
-
Uses free struct in partial slab
-
If none, takes one from empty slab
-
If no empty slab, create new empty
-
Slab Allocator in Linux (Cont.)
- Slab started in Solaris, now wide-spread for both kernel mode and user memory in various OSes
- Linux 2.2 had SLAB, now has both SLOB and SLUB allocators
- SLOB for systems with limited memory
- Simple List of Blocks – maintains 3 list objects for small, medium, large objects
- SLUB is performance-optimized SLAB removes per-CPU queues, metadata stored in page structure
- SLOB for systems with limited memory
Other Considerations – Prepaging
- Prepaging
- To reduce the large number of page faults that occurs at process startup
- Prepage all or some of the pages a process will need, before they are referenced
- Bring in last working set
- But if prepaged pages are unused, I/O and memory was wasted
- Assume s pages are prepaged and α of the pages is used
- Is cost of s * α save pages faults > or < than the cost of prepaging s * (1- α) unnecessary pages?
- α near zero => prepaging loses
Other Issues – Page Size
- Sometimes OS designers have a choice
- Especially if running on custom-built CPU
- Page size selection must take into consideration:
- Memory utilization : favors small page, internal fragmentation
- Page table size : : favors larger pages (fewer entries)
- Resolution
- I/O overhead
- Transfer once located pages relatively fast
- favor large pages
- Transfer once located pages relatively fast
- Number of page faults: : favor larger pages
- Locality
- Favors small pages because
- Better estimate of locality
- Remind portions job which are not being used
- Favors small pages because
- TLB size and effectiveness
- Always power of 2, usually in the range 212 (4,096 bytes) to 222 (4,194,304 bytes)
- On average, growing over time
Other Issues – TLB Reach
- TLB Reach - The amount of memory accessible from the TLB
- TLB Reach = (TLB Size) X (Page Size)
- Ideally, the working set of each process is stored in the TLB
- Otherwise there is a high degree of page faults
- Increase the Page Size
- This may lead to an increase in fragmentation as not all applications require a large page size
- Provide Multiple Page Sizes
- This allows applications that require larger page sizes the opportunity to use them without an increase in fragmentation
Other Considerations
- How many pages allocated to a job?
- Minimum is related to architecture
- PDP-8: at most 1 memory address in an instruction
- 1 page instruction, 2 page operand (indirection) -> 3 page
- PDP-11
- 2 memory addresses in instruction
- Instruction could be 2 or 3 words long
- » 2 pages for instruction, 4 pages for operands
- => 6 pages
- » 2 pages for instruction, 4 pages for operands
- PDP-8: at most 1 memory address in an instruction
- Minimum is related to architecture
Other Consideration (Cont.)
- Thrashing
- More time spent moving pages in & out of memory than doing actual work
- Occurs when too few frames allocated to job
- Situation can be made worse by CPU scheduling strategy
- Since jobs in I/O queue when waiting for pages, CPU can become under-utilized
- More jobs can be brought into system, further degrading performance
- Too many pages
- It is possible to have too low fault rate
- Memory. CPU under-utilized
Other Consideration (Cont.) - XXXX
- Page size selection
- table size : favors larger pages (fewer entries)
- Memory utilization: favors small page, internal fragmentation
- I/O overhead
- Transfer once located pages relatively fast
- favor large pages
- Locality
- Favors small pages because
- Better estimate of locality
- Remind portions job which are not being used
- Favors small pages because
- Page fault : favor larger pages •
- Trend is toward larger page size
- Cpu speed, MM increasing faster than disk speed
- Page faults are more costly today
Other Consideration (Cont.)
- Program structure

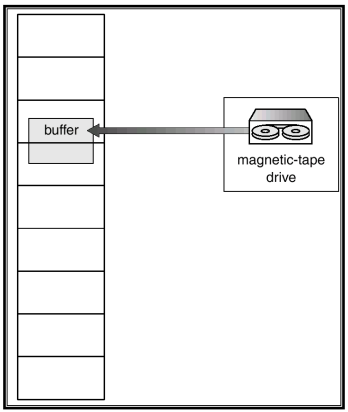
Other Issues – I/O interlock - XXXX
- I/O interlock and addressing
- Consider I/O - Pages that are used for copying a file from a device must be locked from being selected for eviction by a page replacement algorithm
- ** When demand paging is used, we sometimes need to allow some of the pages to be locked in memory
- A process issues an I/O request, and is put in a queue for that I/O device
- Meanwhile CPU is given to other processes
- These processes cause page fault, uses global replacement
- One of them replaces the page containing the memory buffer for the waiting process
- The pages are paged out
- Later, when the I/O request advances to the head of the device queue, I/O occurs to the specified address
- However, this frame belongs to another process
- Solution
- Never to execute I/O to user memory: copy overhead (system memory, I/O device)
- Allow pages to be locked into memory : do not select for replacement
- Between high & low priority processes
Reason Why Frames Used For I/O Must Be In Memory - XXXX
Demand Segmentation - XXXX
- Demand paging is the most efficient virtual memory system
- Used when insufficient hardware to implement demand paging.
- Intel 80286 does not include paging features, but does have segments
- OS/2 allocates memory in segments, which it keeps track of through segment descriptors
- Segment descriptor contains a valid bit to indicate whether the segment is currently in memory.
- If segment is in main memory, access continues,
- If not in memory, segment fault.
댓글남기기